发布日志v2.1
2025-2-17 About 60 min
# 数据源
# HTTP数据源配置自定义解析器方案
HTTP接口请求作为数据集尽管我们已经尽可能的支持多种数据结构解析场景,如:
- 返回类型是JSON对象
- 数据字段为JSONObject数组
- 数据字段为原始数据二维数组
- 请求返回JSON数组的场景
- 数组中元素为原始数据类型
- 数组中元素为JSON对象数据类型
但是还是会遇到一些预设覆盖不到的场景,因此我们这次除了例行增加一些常见数据结构解析之外,(如:兼容返回内容非json文本的单个数字解析), 这次我们提供了自定义解析器方案,把主动权交给用户
首先我们解耦了HttpResponseParser部分代码,并基于gitee对外发布依赖jar [ibi-ext.jar], 用户可以通过Maven引入依赖库与依赖,之后自定义解析器
- 增加maven repository
<repositories>
<repository>
<id>ibi-ext-gitee</id>
<url>https://gitee.com/chuguotech/ibi-ext/raw/master/releases</url>
</repository>
</repositories>
1
2
3
4
5
6
2
3
4
5
6
- 增加依赖
<dependencies>
<dependency>
<groupId>com.chuguotech</groupId>
<artifactId>ibi-ext</artifactId>
<version>1.0.0</version>
</dependency>
</dependencies>
1
2
3
4
5
6
7
2
3
4
5
6
7
样例
package org.example;
import org.cboard.plugins.http.parser.HttpResponseParser;
import org.cboard.plugins.http.parser.ParserResult;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
public class MyResultParser2 implements HttpResponseParser {
@Override
public ParserResult parseResponse(Map<String, String> query, String response) {
ParserResult result = new ParserResult();
List<List<Object>> data = result.getData();
// 表头
List<Object> header = Arrays.asList("c1", "c2");
data.add(header);
// Mock Response 返回数据
Object[][] dataArr = {
{"a", 2},
{"b", 3},
{"c", 5}
};
for (Object[] objects : dataArr) {
data.add(Arrays.asList(objects));
}
return result;
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 数据集
# 重要 基于DuckDB的新一代缓存策略
- 轻量级、列式存储
- 比H2数据库更加稳定
- 统一函数适配
- 百万数据读取之后秒级极速加载, 速度提升数十倍
- 百万数据单机秒级极速查询
- 数据加载字段级容错处理
- 数值类型字段加载支持带货币、千分位等非数字符号的场景
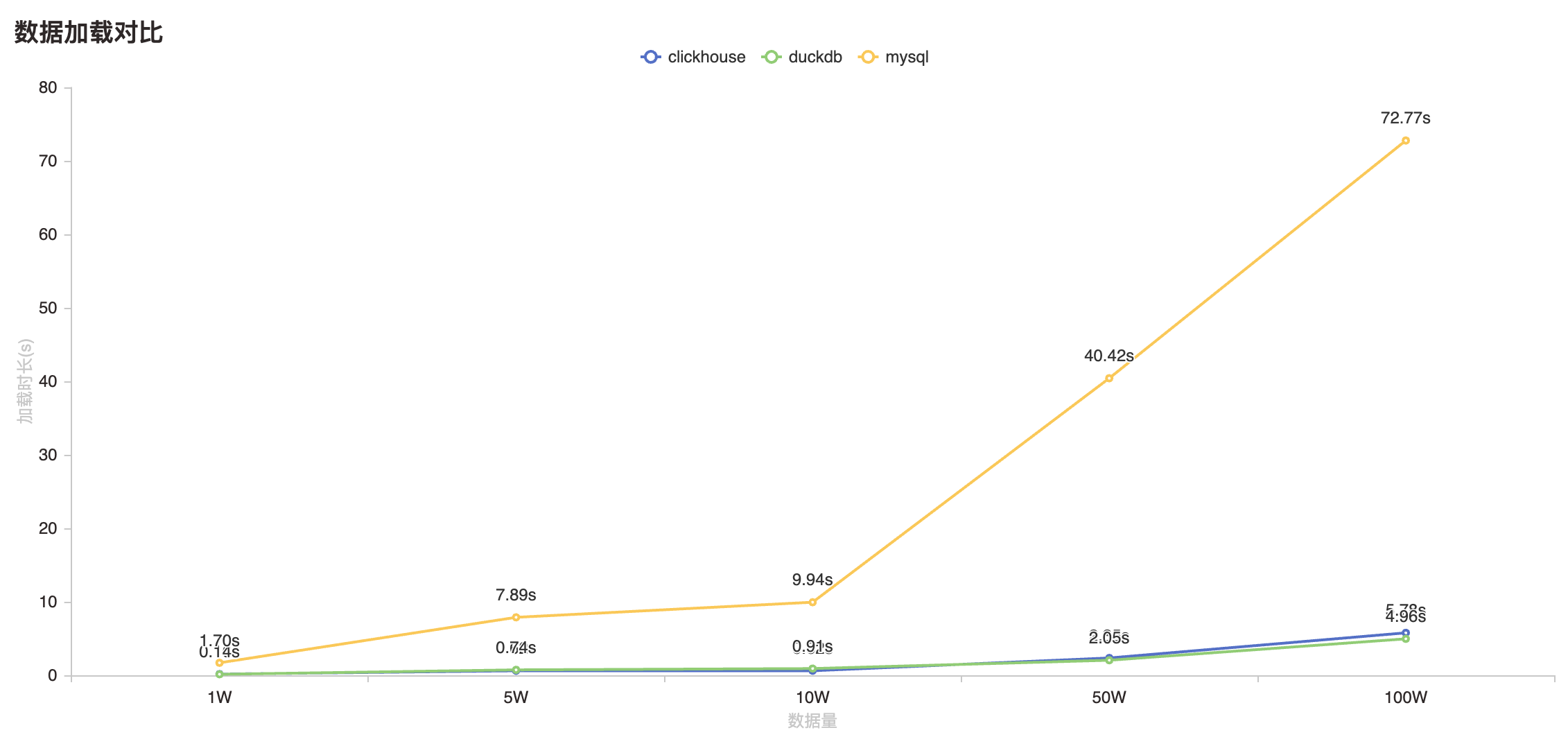
下面是数据加载测试对比图,测试环境,硬盘为NVMe PCIe 4.0, 读写速度为5GB/s,
为了减少数据源SQL查询性能的干扰,测试选定一张大表通过,select * limit 查询数据
select * from foodmart.sales_fact_200w limit 10000
1
通过下图可以看出mysql在数据量过多之后加载时间显著上升,而DuckDB和Clickhouse 50W、100W数据加载时长都能控制在5s以内,考虑到数据体量用户体感非常不错
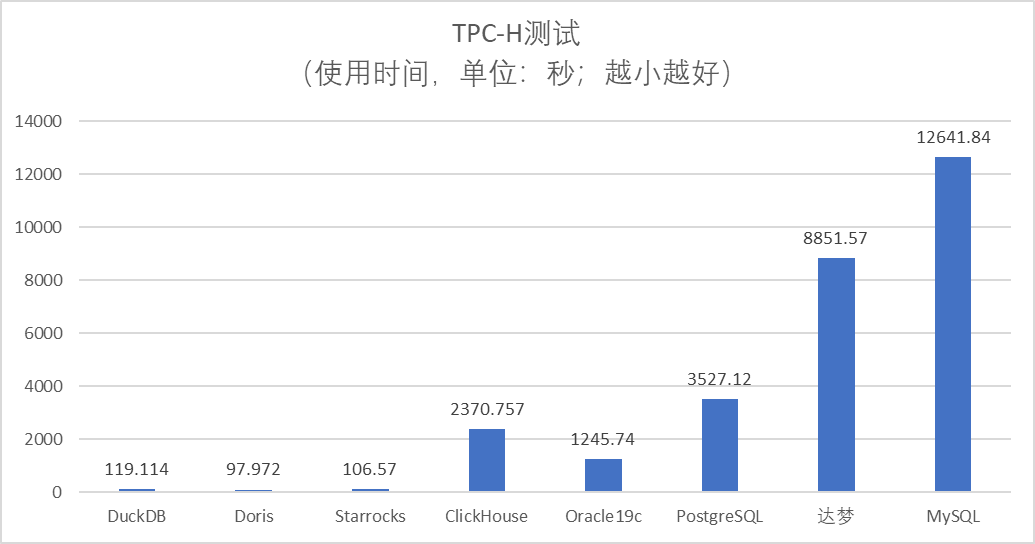
此外,在网友TPC-H 200G数据(非标准测试) 中DuckDB也取得了非常好的成绩, 具体参考 (opens new window)
Starrocks、Doris、DuckDB是目前OLAP引擎中第一梯队,可以轻松处理TPC-H的任务。
# 汇总LOD,合并相同颗粒度LOD
2.0从0到1实现LOD表达式,得到用户的广泛好评与认可,分析能力大幅度提高,但也反馈一些小问题,比如相同颗粒度的LOD表达式查询时独立查询, 这样即影响SQL性能也不便于查询语句分析
如下面两个LOD表达式, 具有相同的颗粒度与过滤条件:
sum({INCLUDE `member_card` : sum(`store_sales`)})
sum({INCLUDE `member_card` : sum(`store_cost`)})
1
2
2
合并前, 每个LOD字段独立计算
-- 查询1
SELECT "gender" AS c_0,
STRFTIME("r_date", '%Y') AS c_1,
"sales_country" AS c_2,
"member_card" AS c_3,
sum("store_sales") AS v_0
FROM cb_view
GROUP BY "gender",
STRFTIME("r_date", '%Y'),
"sales_country",
"member_card"
-- 查询2
SELECT "gender" AS c_0,
STRFTIME("r_date", '%Y') AS c_1,
"sales_country" AS c_2,
"member_card" AS c_3,
sum("store_cost") AS v_1
FROM cb_view
GROUP BY "gender",
STRFTIME("r_date", '%Y'),
"sales_country",
"member_card"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
合并之后, 相同颗粒度一次查询
SELECT "gender" AS c_0,
STRFTIME("r_date", '%Y') AS c_1,
"sales_country" AS c_2,
"member_card" AS c_3,
sum("store_sales") AS v_0, sum("store_cost") AS v_1
FROM cb_view
GROUP BY "gender",
STRFTIME("r_date", '%Y'),
"sales_country",
"member_card"
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
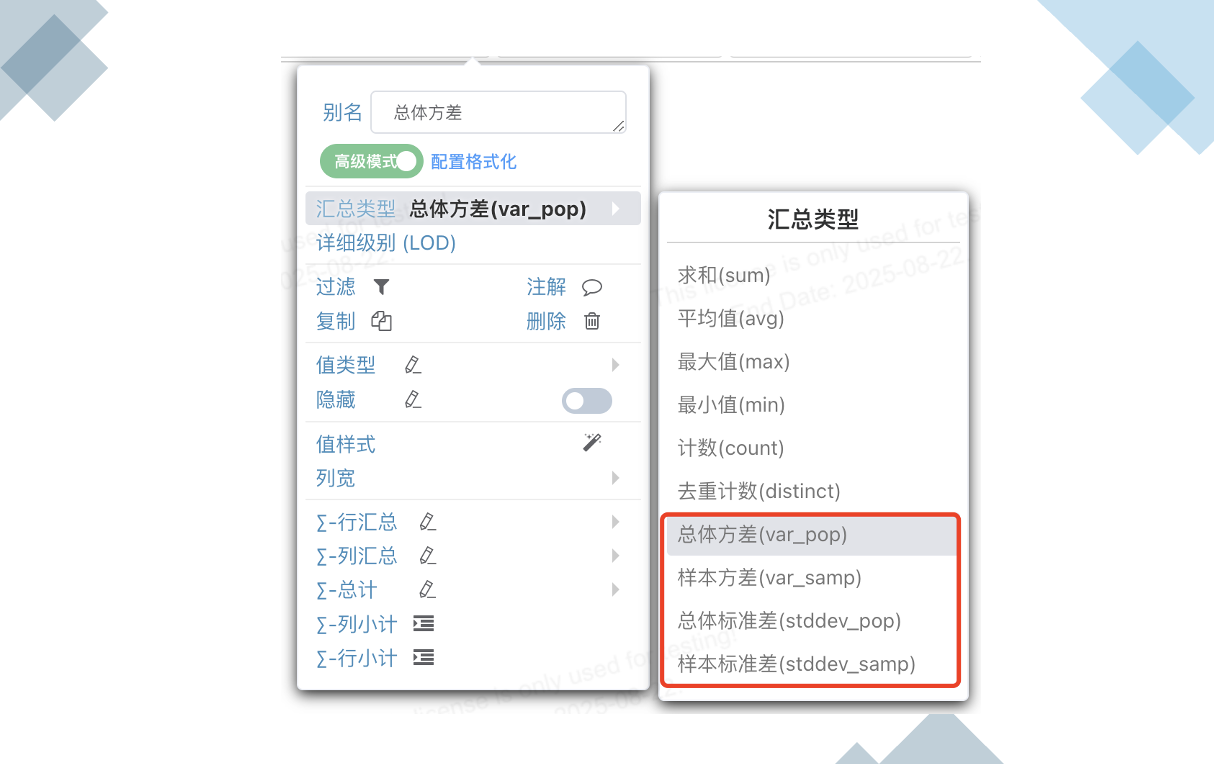
# 汇总类型支持方差、标准差
增加总体方差、样本方差、总体标准差、样本标准差汇总配置,适配下列数据库
- MySQL
- Doris
- H2
- Clickhouse
- Oracle
- Dameng
- PostgreSQL
- SQLServer
- Presto
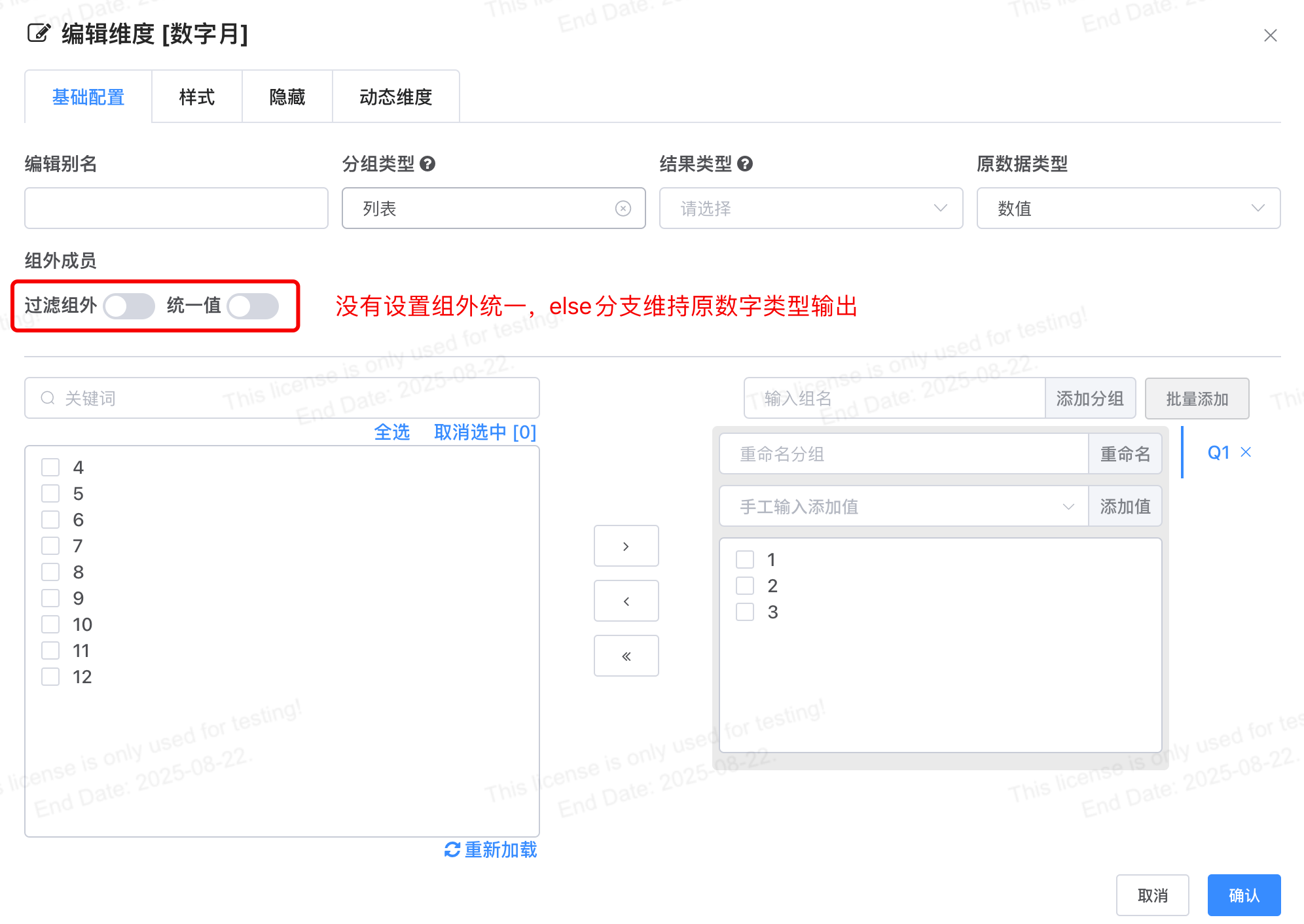
# [优化] 衍生维度其他成员维持原值时转字符
衍生维度其他成员维持原值时转字符,避免sql case when分支数据类型不一致时报错
在 SQL 中,CASE WHEN 表达式用于基于条件选择不同的结果。在一些情况下,CASE 分支的返回类型不一致时,可能会导致错误。这通常是因为 SQL 引擎期望每个分支返回的结果类型一致。当类型不一致时,SQL 引擎可能无法决定最终的返回类型,从而引发错误。
SELECT CASE
WHEN condition THEN 'text' -- 返回字符串类型
ELSE month -- 返回整数类型
END AS result
FROM my_table;
1
2
3
4
5
2
3
4
5
为了避免这种问题我们为不同数据库做了字段转字符统一处理
SELECT CASE
WHEN condition THEN 'text' -- 返回字符串类型
ELSE CAST(month AS VARCHAR) -- 转化为字符, 不同的数据库调用不同的数值类型转换函数
END AS result
FROM my_table;
1
2
3
4
5
2
3
4
5
# 自助分析
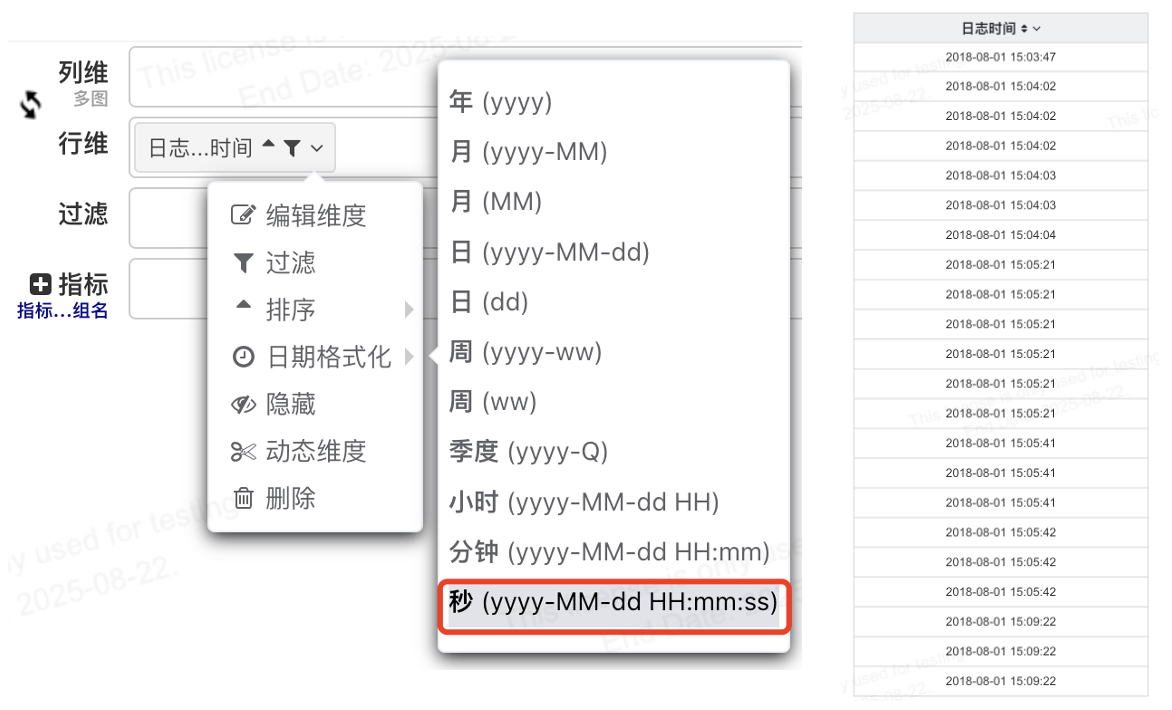
# 日期字段格式化支持到秒
日期字段格式化支持到秒, 用于明细表数据展示
# 交叉表
# 对齐方式统一配置
- 对齐方式统一配置,不再由字段独立配置,区分行表头、列表头、指标头、指标统一配置对齐
- 一方面减少了配置操作,统一了不同类型的单元格对齐配置
- 同时解决了原来指标头和数值对齐方式不能分开配置的问题

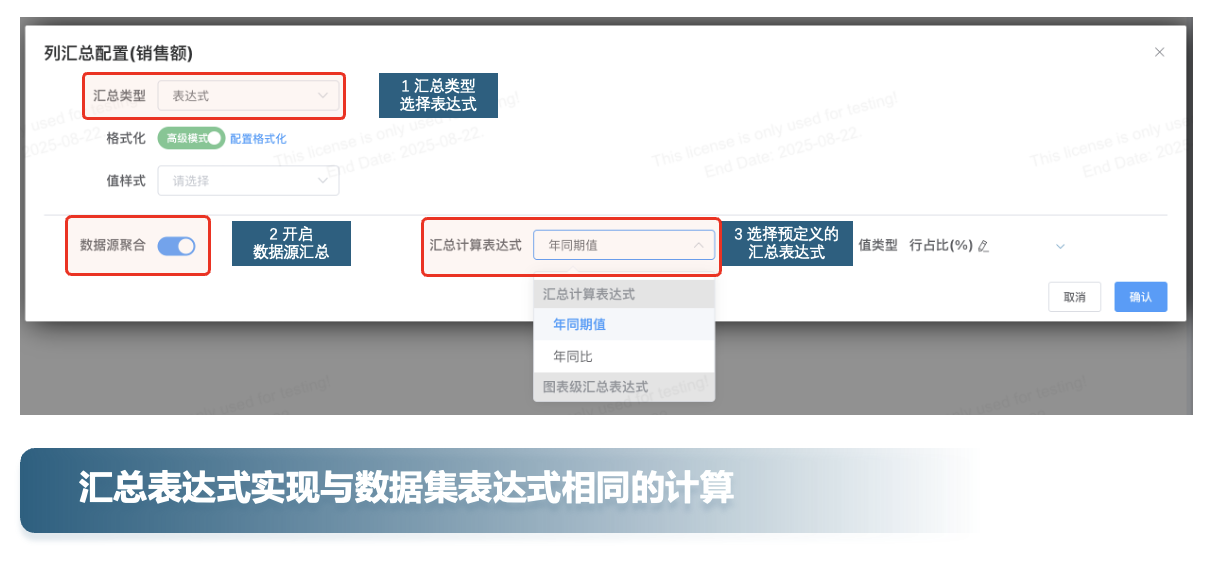
# 重要 汇总表达值配置数据集汇总表达式
这个功能的增强是针对 交叉表汇总表达式计算 进行的优化,旨在解决 表面数据计算 的局限性,并提供更强大的 数据源端计算支持。
问题背景:
- 之前的汇总表达式配置:
- 在早期版本中,虽然已经支持在 表面数据 进行汇总表达式的配置,但其 功能性受限,特别是对于一些无法用表面数据得出的汇总计算(如 COUNT(DISTINCT xxx))无法处理。
- 此外,表面数据计算的 表达式语法存在局限,无法像数据源端计算那样灵活。这导致用户在复杂的数据汇总需求面前,难以使用简单的表达式来满足要求。
新增功能:数据源端汇总表达式计算支持
通过在 数据源端进行计算,解决了上述问题,提供了以下优势:
1. 更强大的计算能力
- 支持复杂计算: 新功能支持更复杂的汇总计算表达式,如 COUNT(DISTINCT xxx)、SUM(CASE WHEN ... THEN ... ELSE ...) 等。以前的表面数据计算无法处理这些复杂的表达式,现在可以通过在数据源端直接进行汇总计算来解决。
- 灵活的计算表达式: 新的汇总表达式可以根据业务需求进行自定义,允许更灵活地处理各种复杂的计算场景,比如动态条件汇总、多表关联等。
2. 语法统一性
- 数据源端的表达式语法与数据源一致: 之前的汇总表达式语法和 数据集汇总表达式语法不一致,这增加了配置的复杂性和理解的难度。现在,汇总表达式的语法与数据源端的表达式语法一致,这保证了计算的一致性和可维护性。
- 消除表面数据与数据源计算差异: 表面数据计算与数据源计算之间的语法差异和功能限制被解决,用户不再需要担心在两个不同的层次上编写不同的语法。
3. 下列汇总支持数据源汇总表达式
- 列汇总表达式
- 行汇总表达式
- 行列小计表达式
- 总计表达式
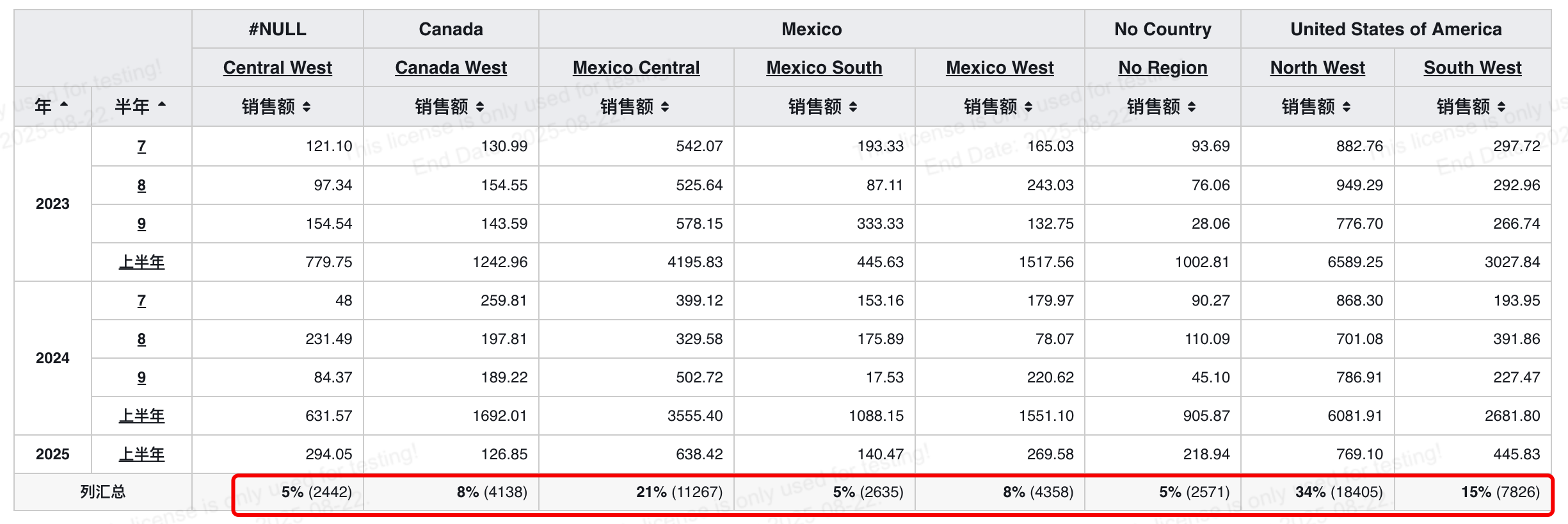
# 行列汇总下推数据源之后值类型变化支持显示原值
汇总级值类型变化之后增加原值显示,用户可以同时看到数据的原始值和经过计算的占比或变化率,进一步提高分析的直观性。
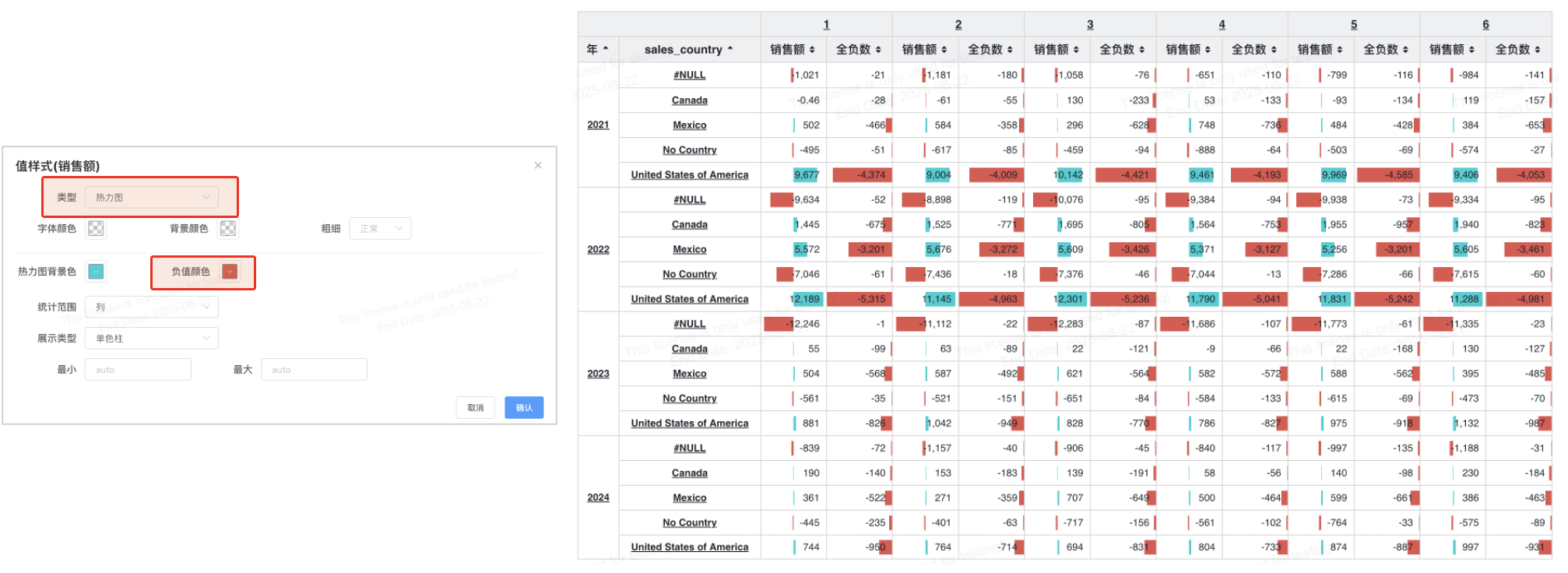
# 表格热力图配置负值颜色
这个功能更新了表格柱形图(热力图)对负值的支持,使得原本仅支持正值的柱形图,能够更加灵活地展示正负数据的变化。新的功能支持正负值条形图 左右分布,并通过 颜色区分正负值,使得数据的可视化效果更加直观。
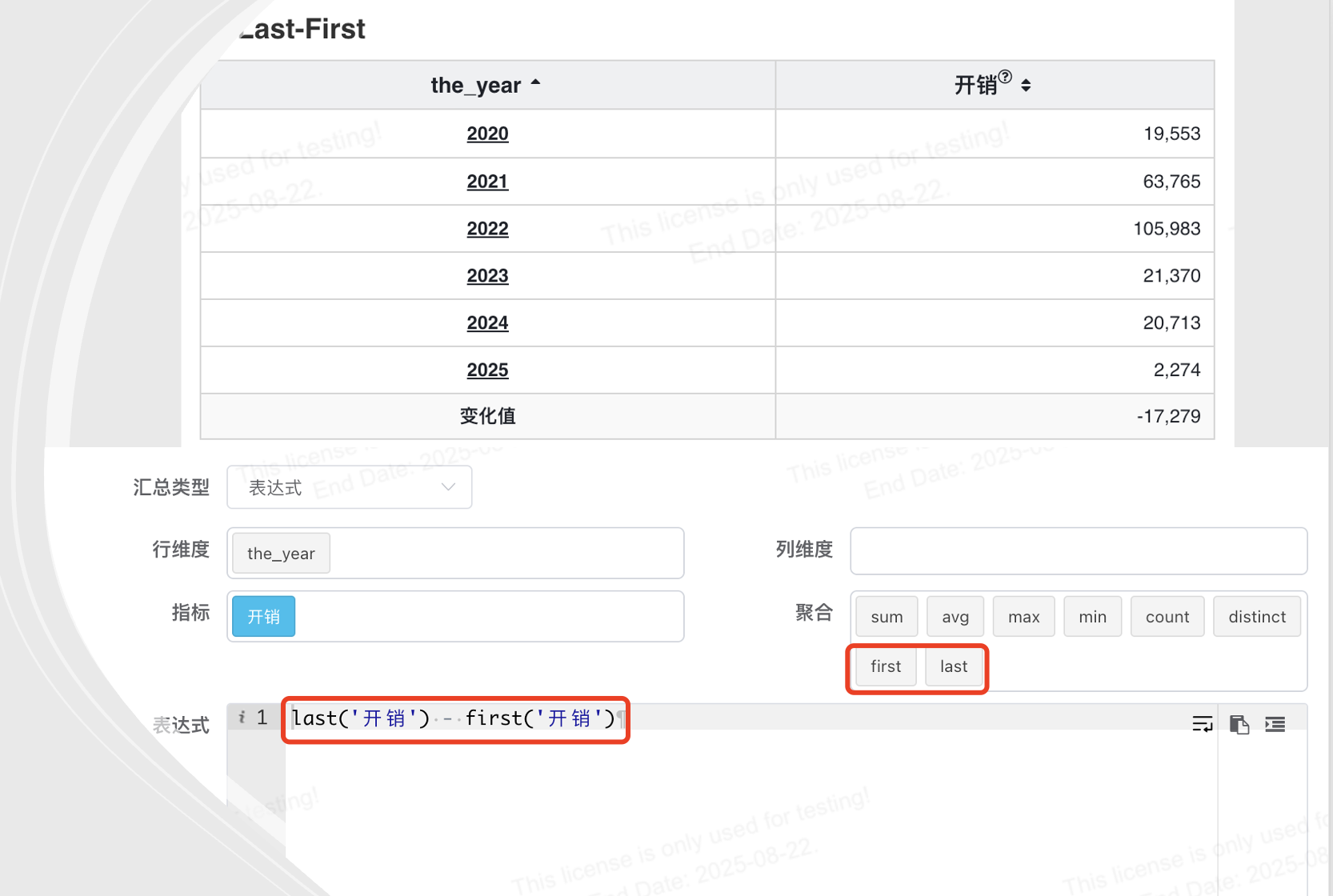
# 表面汇总表达式增加first, last函数支持
在 表面汇总函数 中增加 first 和 last 函数是为了方便获取某一组数据中的 第一个值 和 最后一个值。
使用场景:
- 时间序列数据: 获取每个用户在某一时间段内的 首次登录时间 或 最后一次购买记录。
- 排序后的数据: 获取每个产品的 最早售出价格 或 最新的库存量。
- 聚合分析: 在分析数据时,可以结合 first 和 last 来查看某些列的初始值或最终值。
# 重要 增强指标卡,指标卡百变配置
# 多指标组合
- 切换风格为朴素
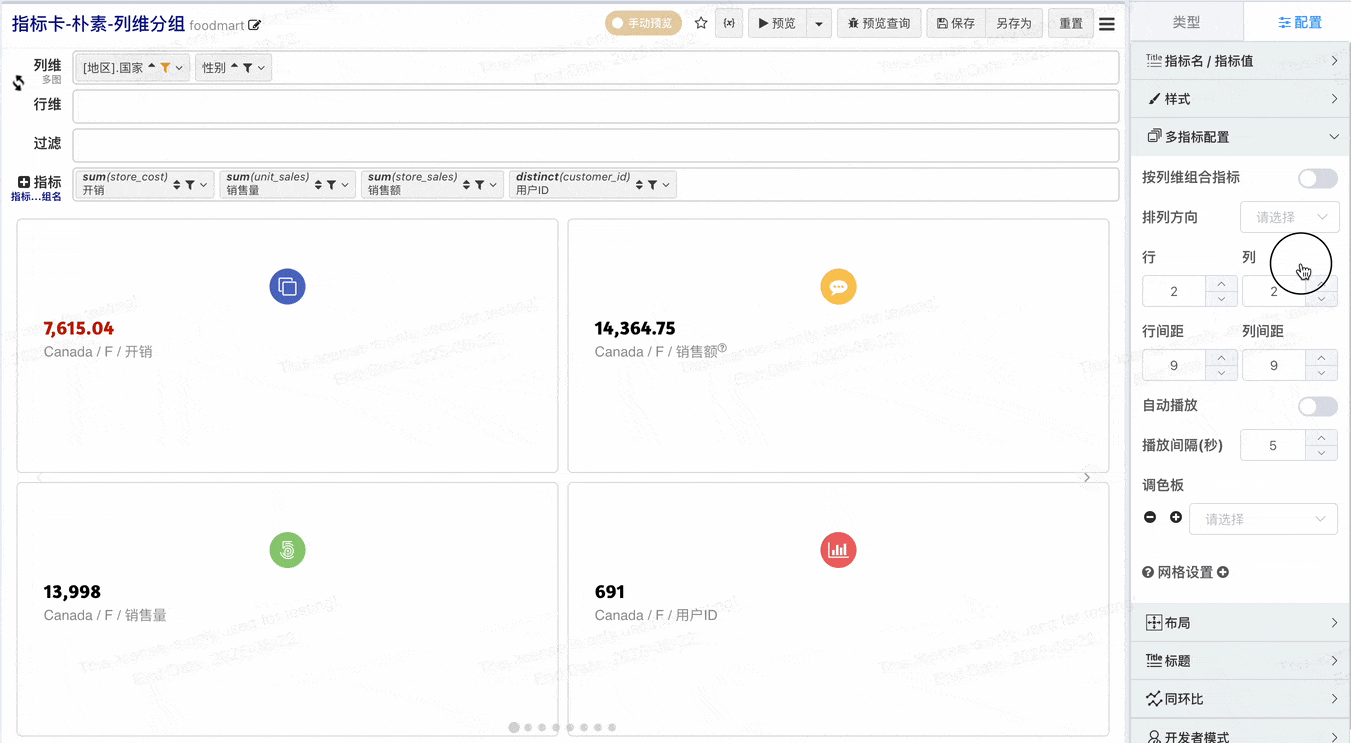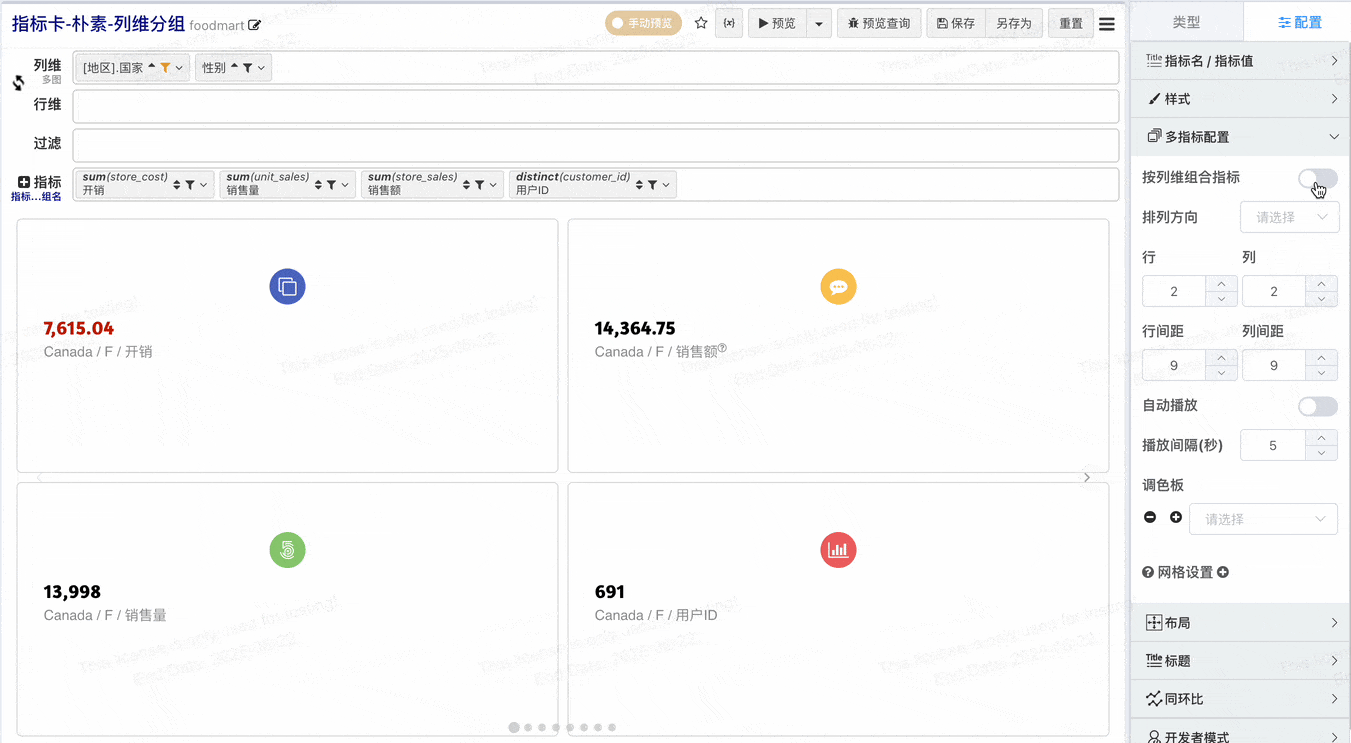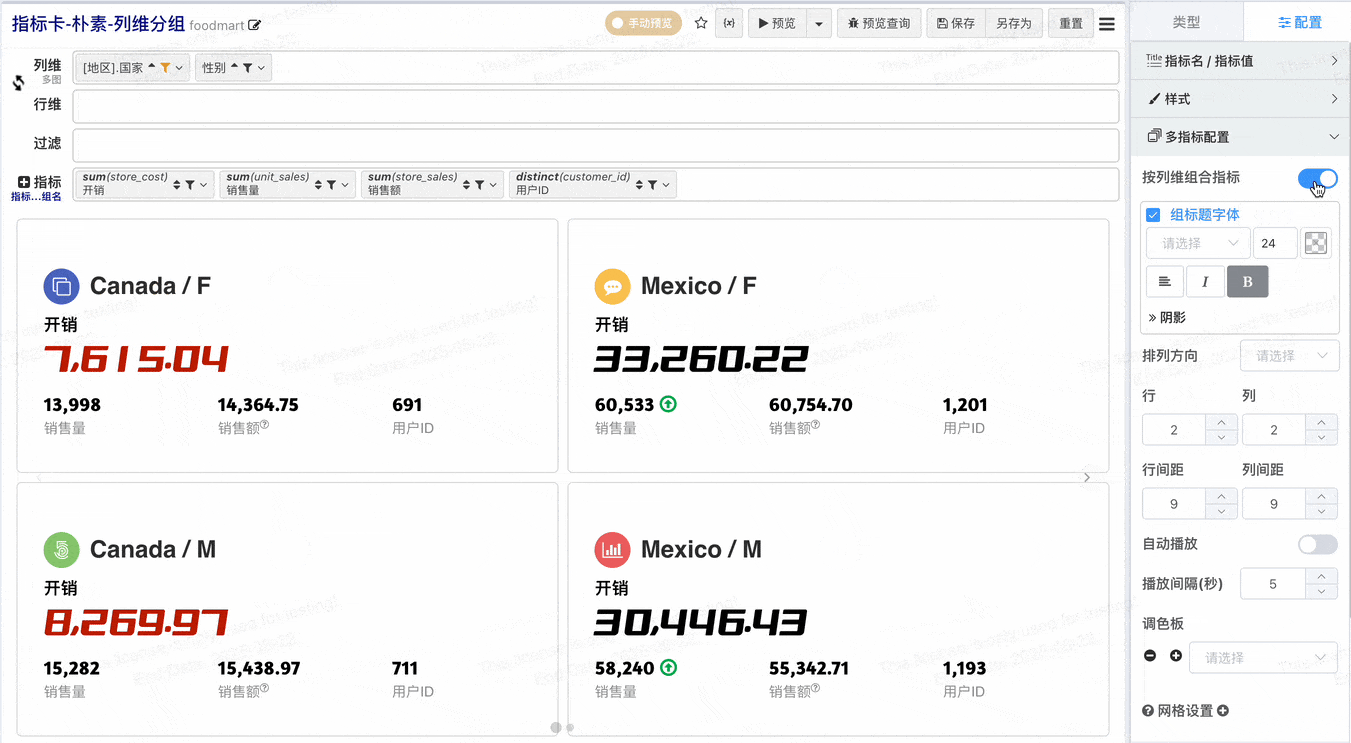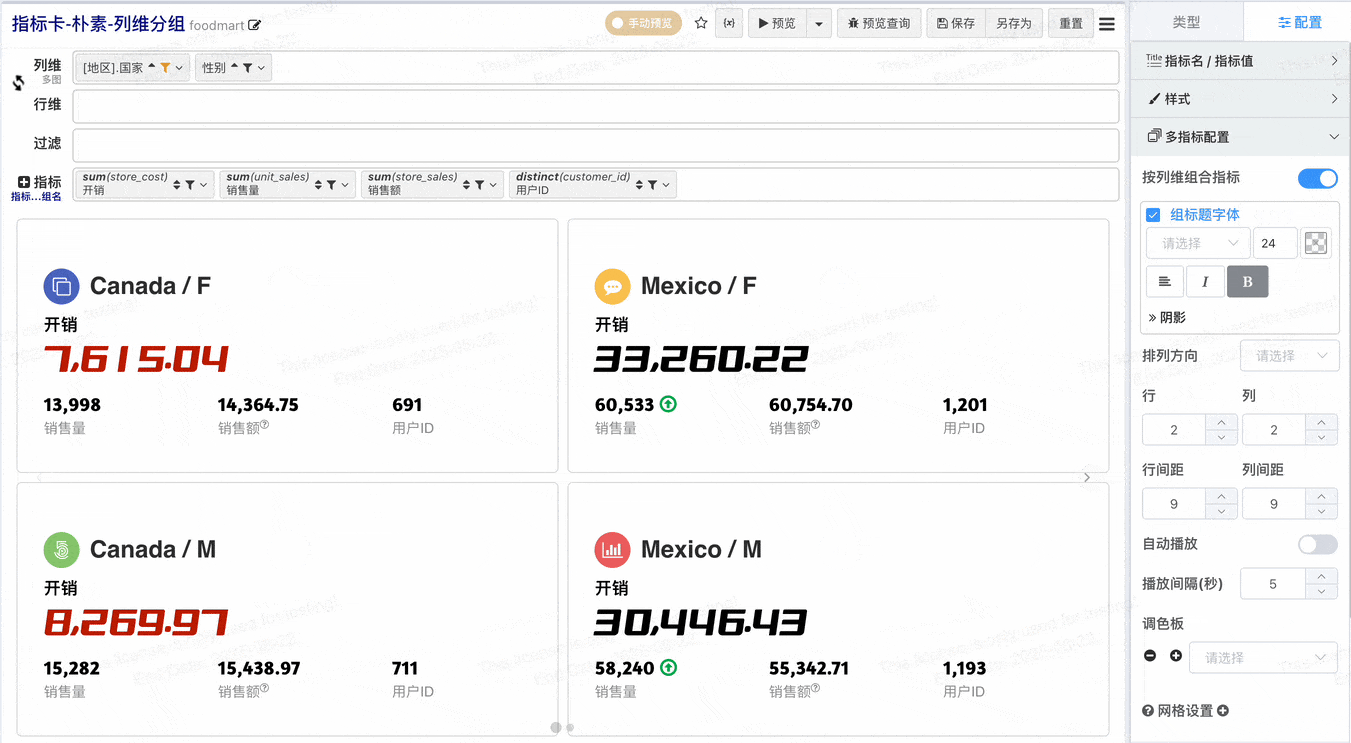
- 在不做指标组合的配置下,每个指标独占一个指标卡,v2.1增加按列维组合指标,开启按列维组合指标之后可以将列维值相同的指标组合显示在一个指标卡
# 按指标栏组合
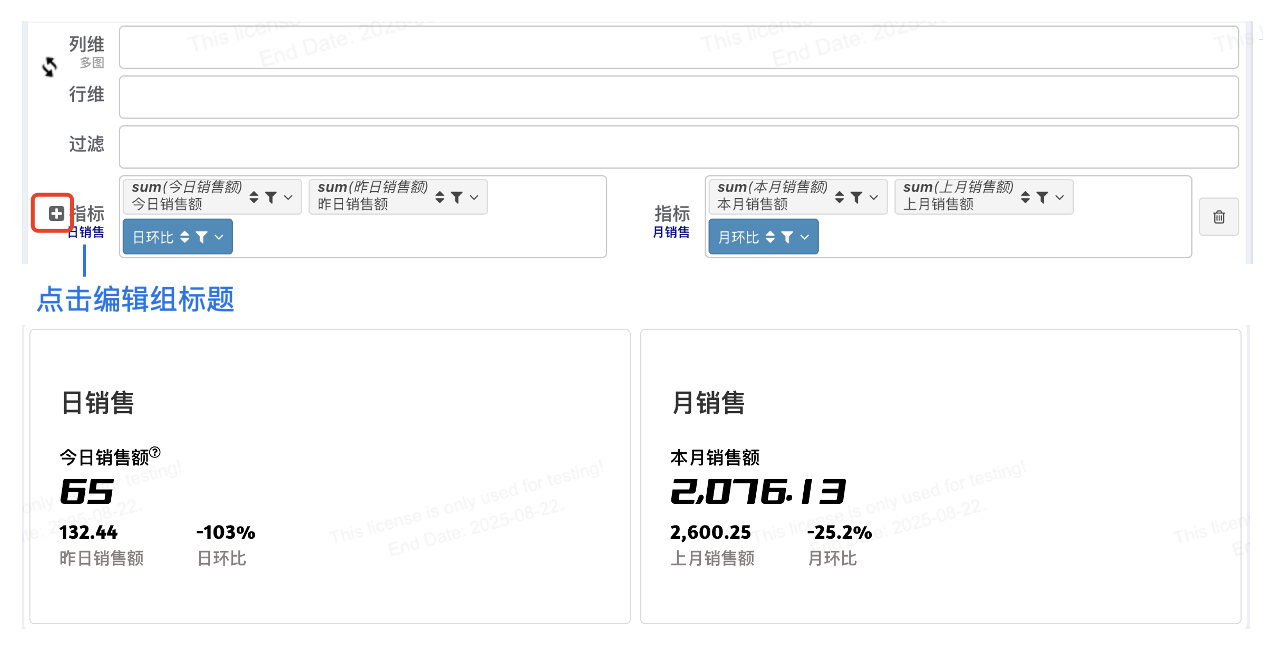
如果没有列维您还可以通过增加指标栏的形式给指标分组
# 指标分页
- 多指标配置网格行、列数
- 当指标卡总数量大于页网格数之后指标自动分页
- 支持配置自动播放与播放时间间隔
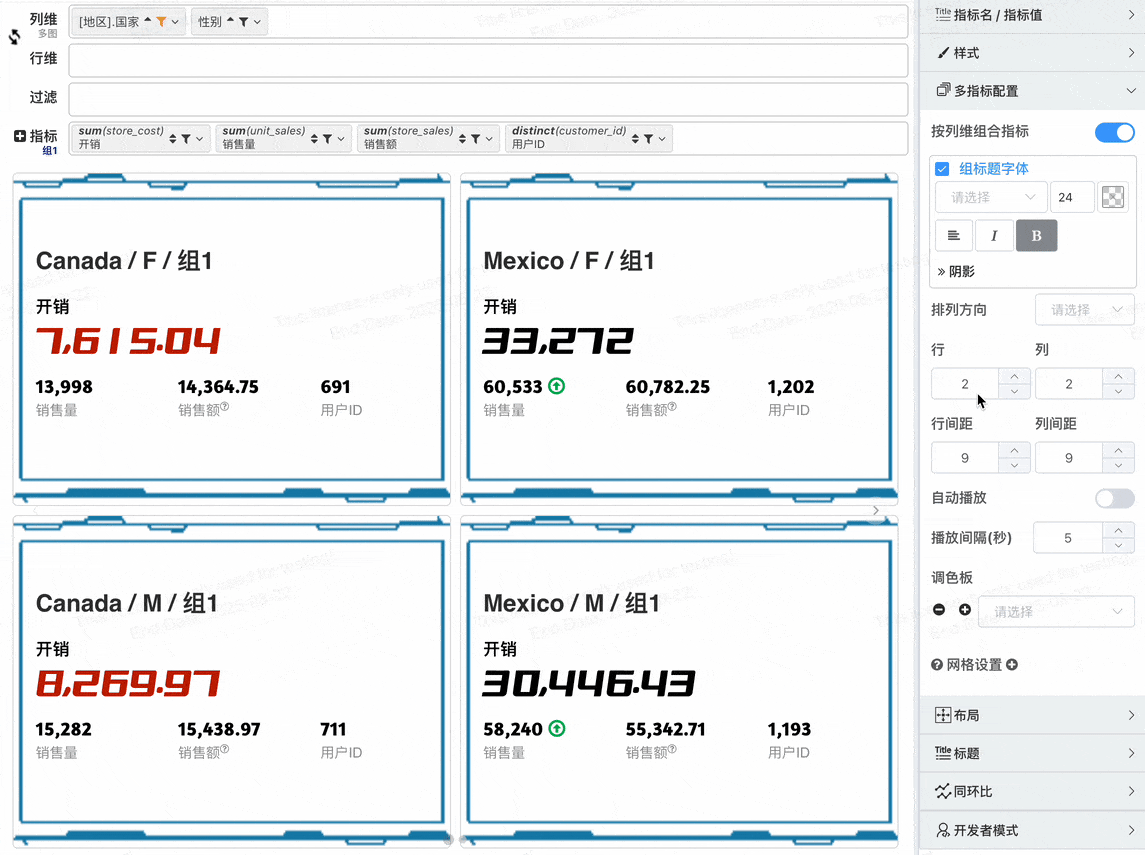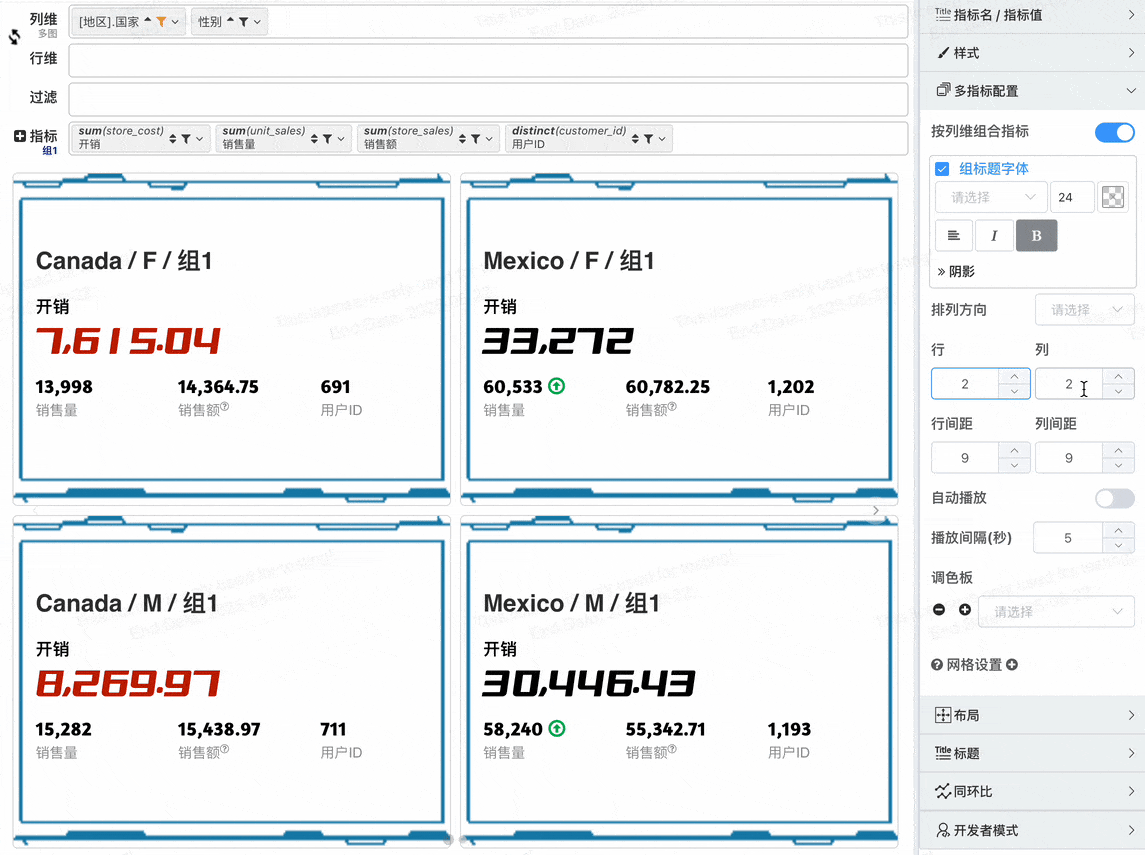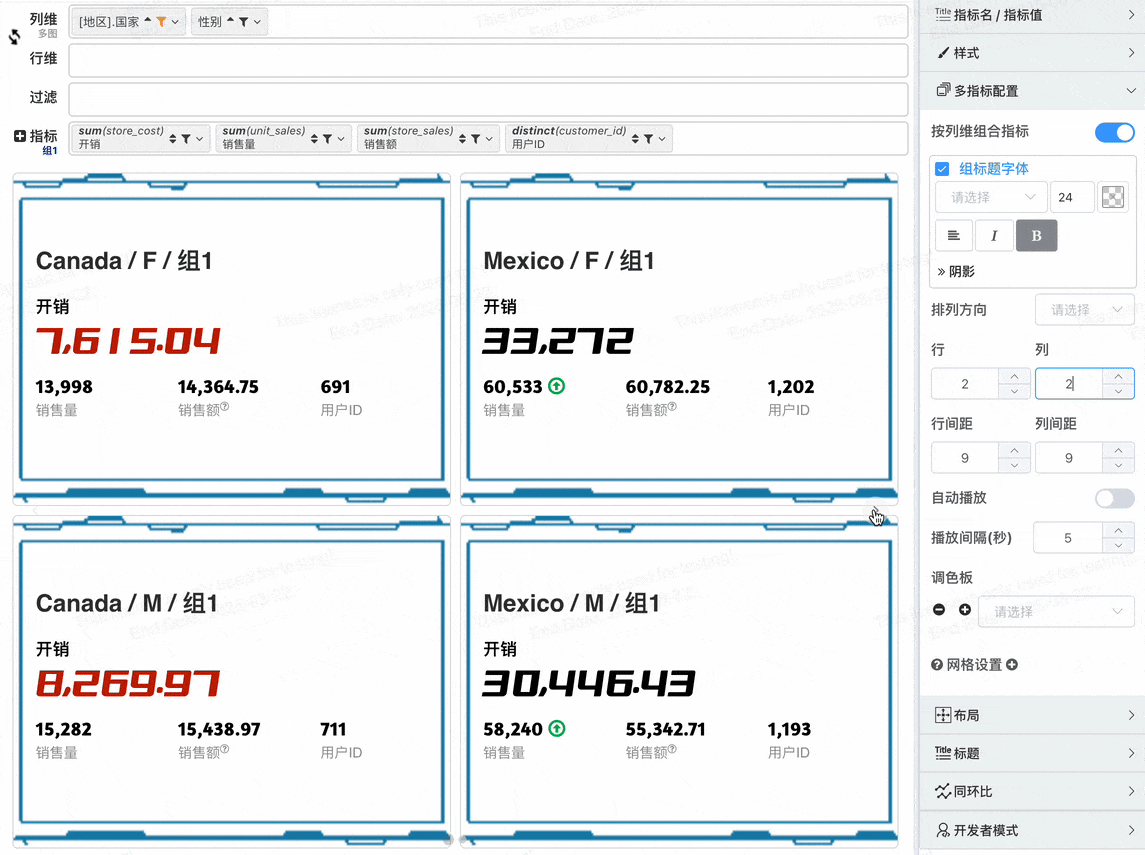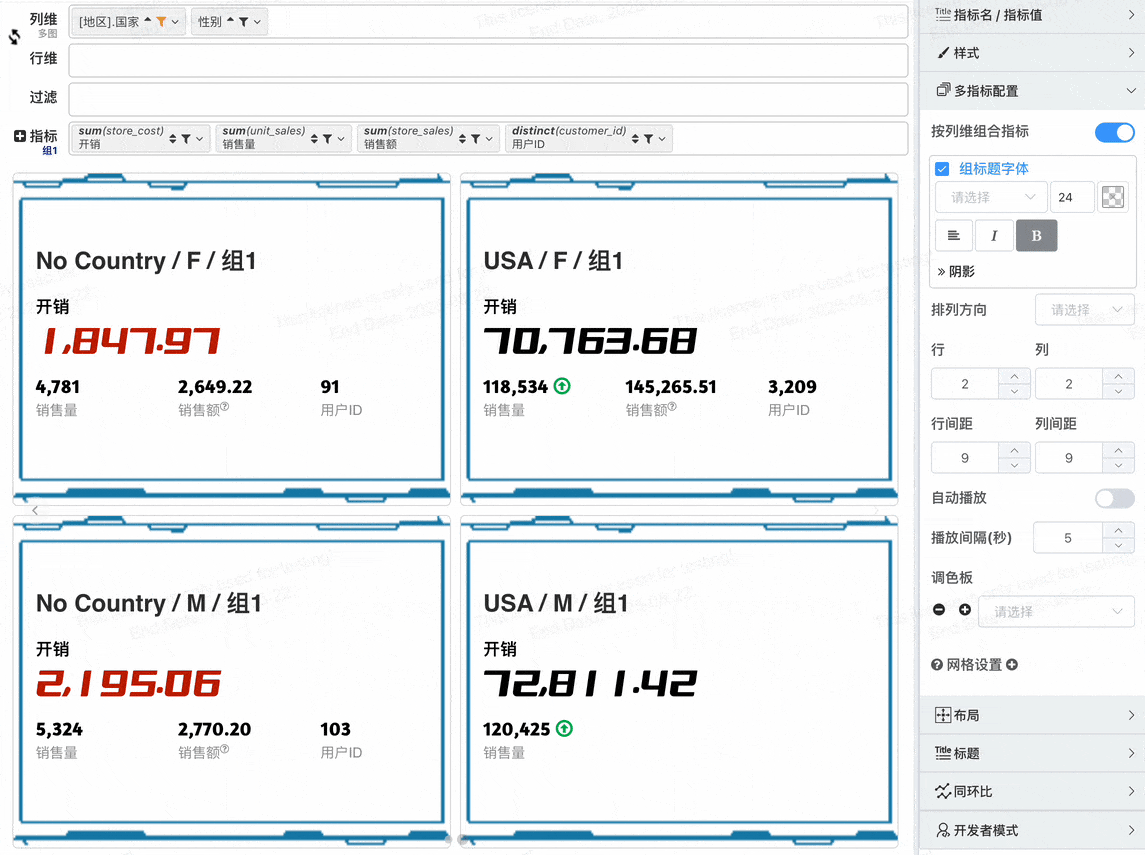
# 多指标卡布局
在开始多指标组合布局之前,先认识一下组合之后的指标卡片元素
- 图标区块
- 主指标区块
- 组标题:组标题可以选择伴随 图标区块 或 指标区块
- 指标组区块
- 每个区块内的元素也可以设置布局与样式

# 布局辅助线
组合指标元素很多,为了方便布局调整,我们提供了布局辅助线,开启辅助线之后可以清晰的观察每个区块、每个元素的位置与大小
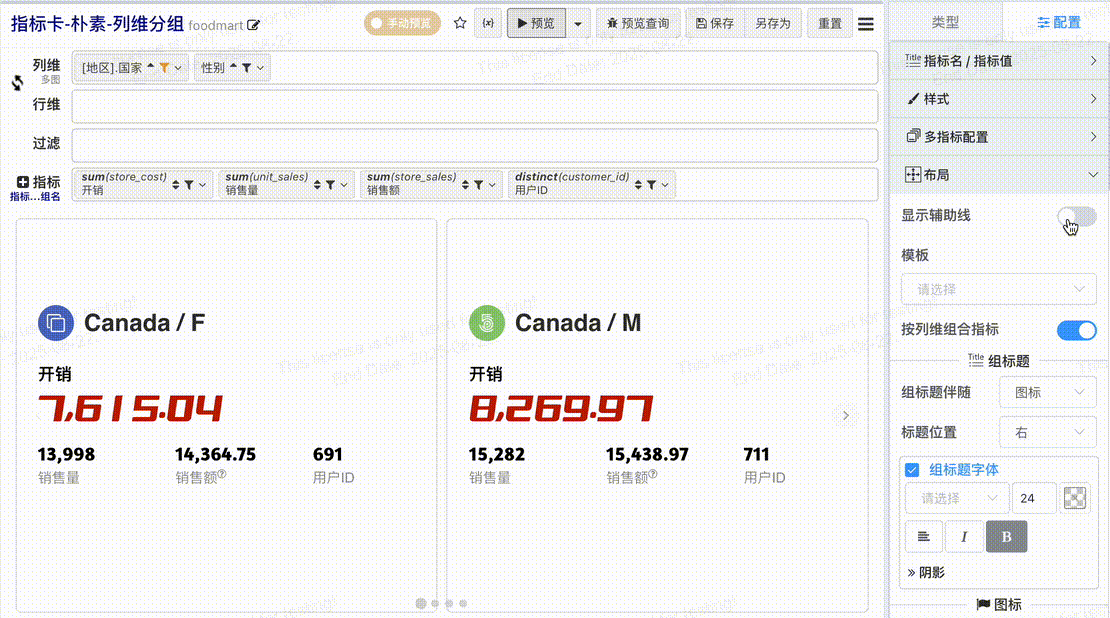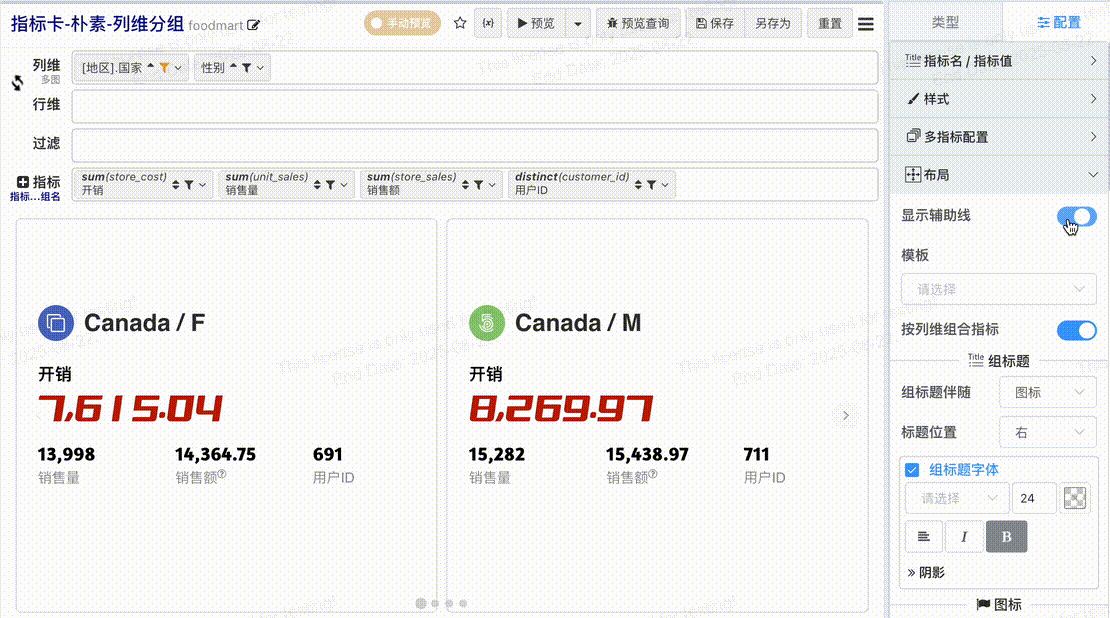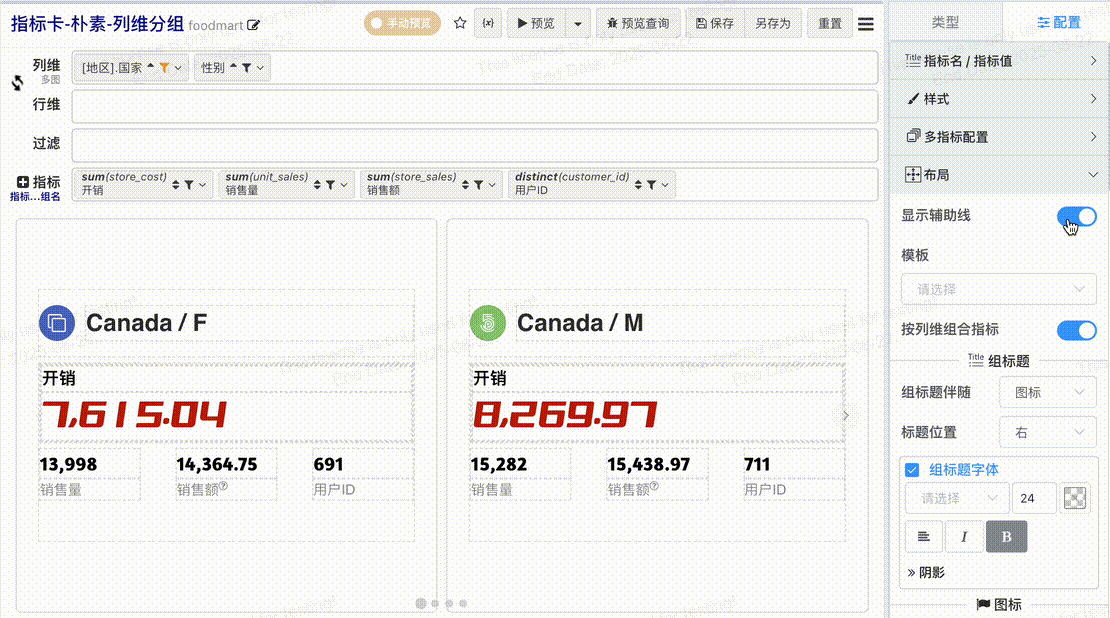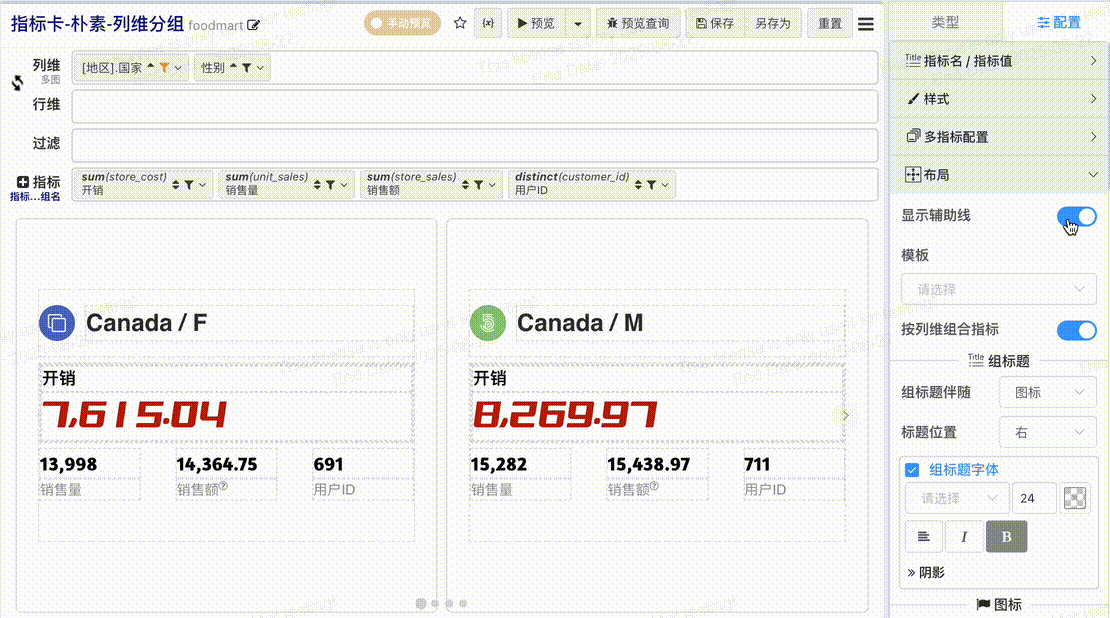
# 组标题配置
- 组标题伴随: 组标题可以选择伴随图标或者指标
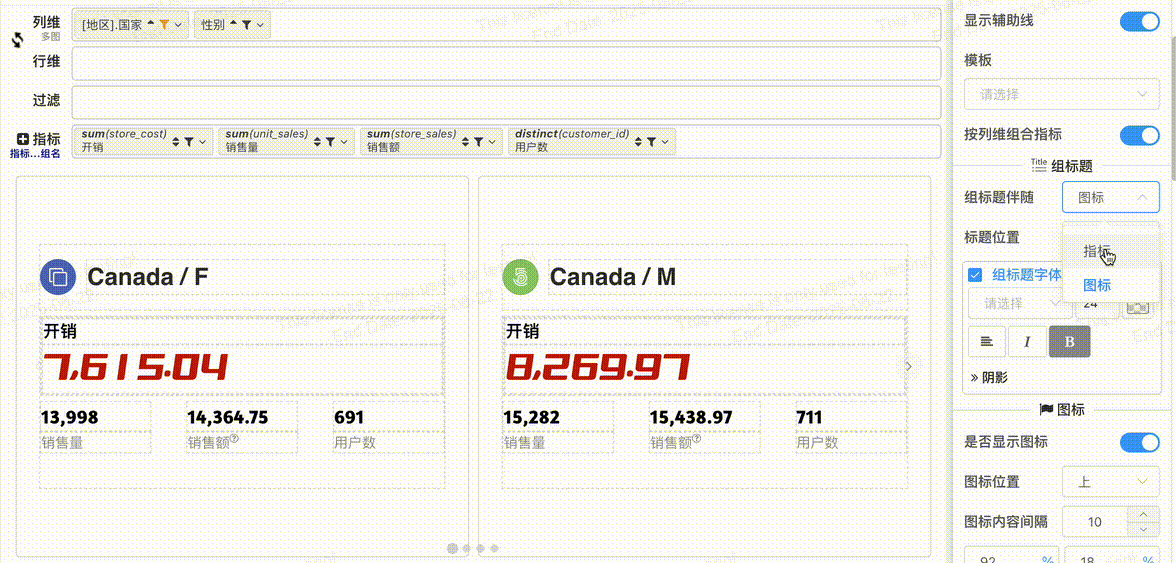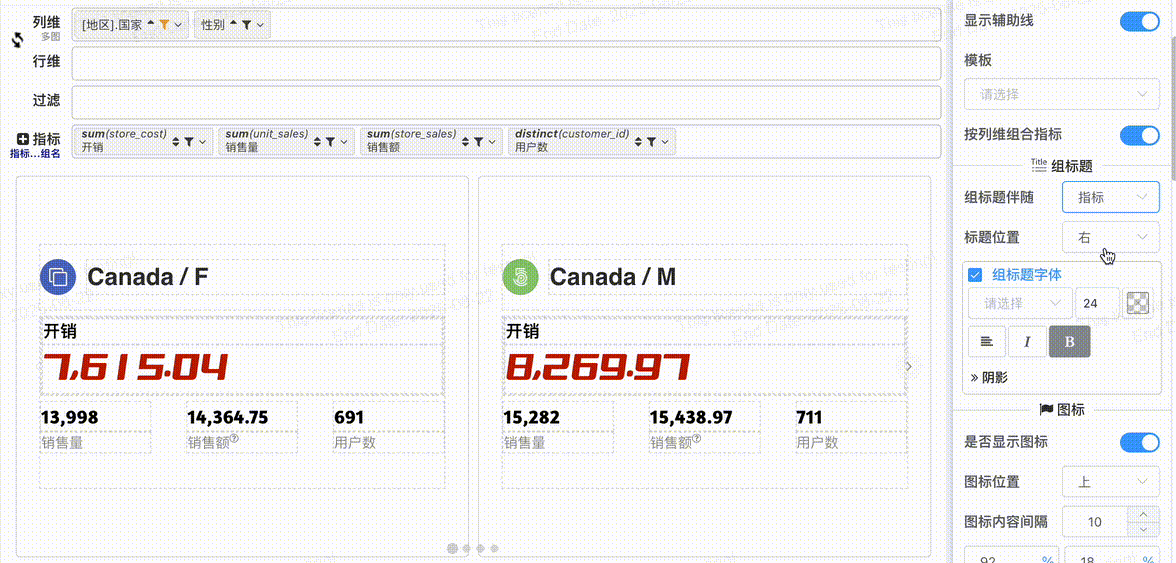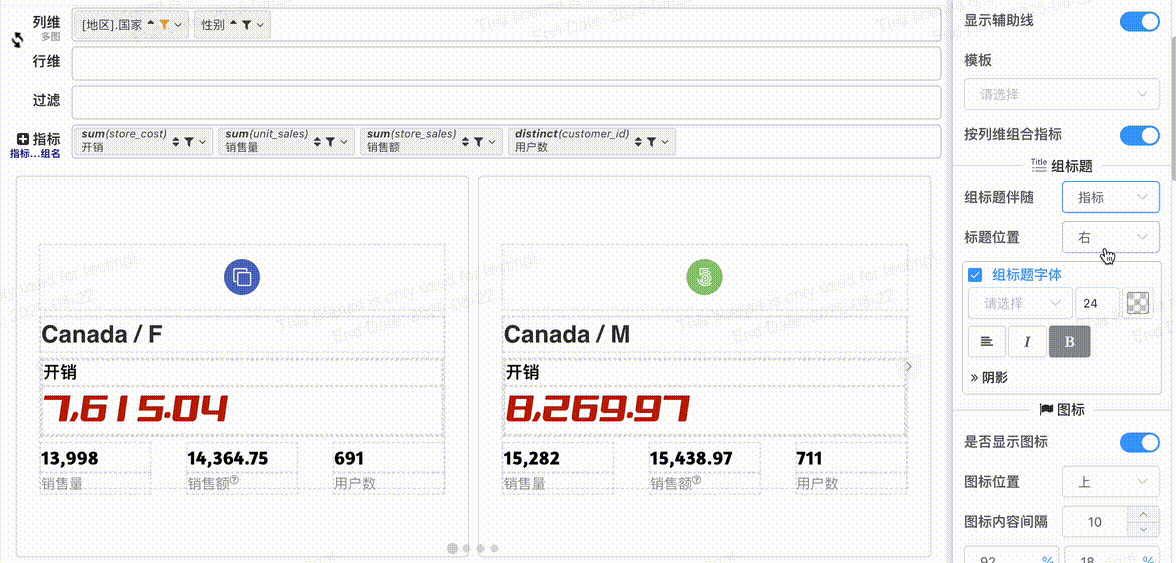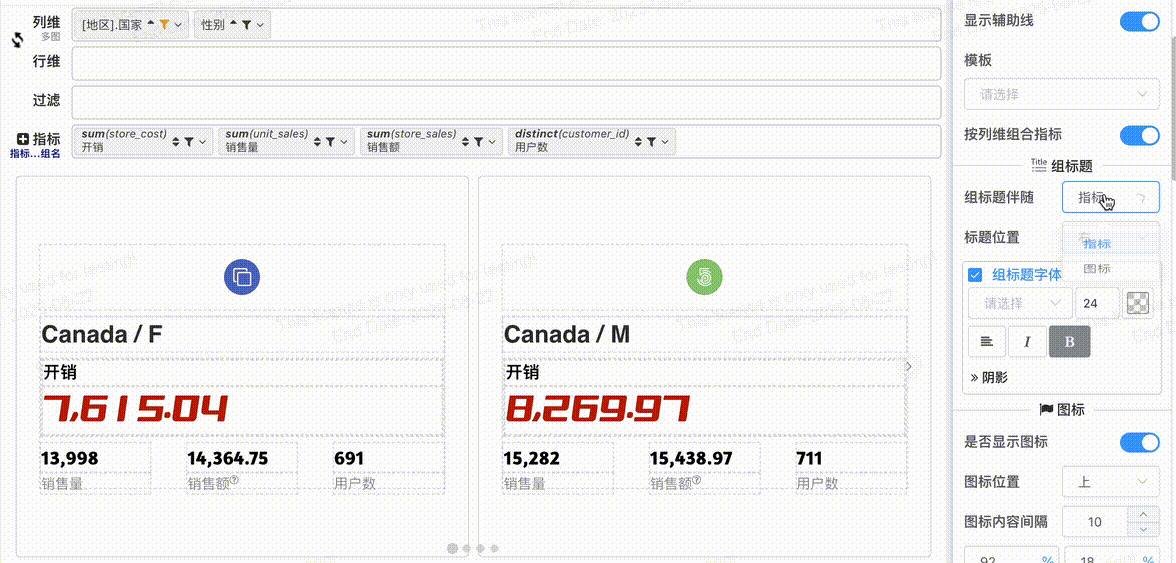
- 组标题位置: 标题伴随图标可以配置围绕图标的位置
- 组标题字体: 组标题字体配置,位于图标上、下时可以配置字体对齐

# 图标区块配置
- 图标区块位置配置
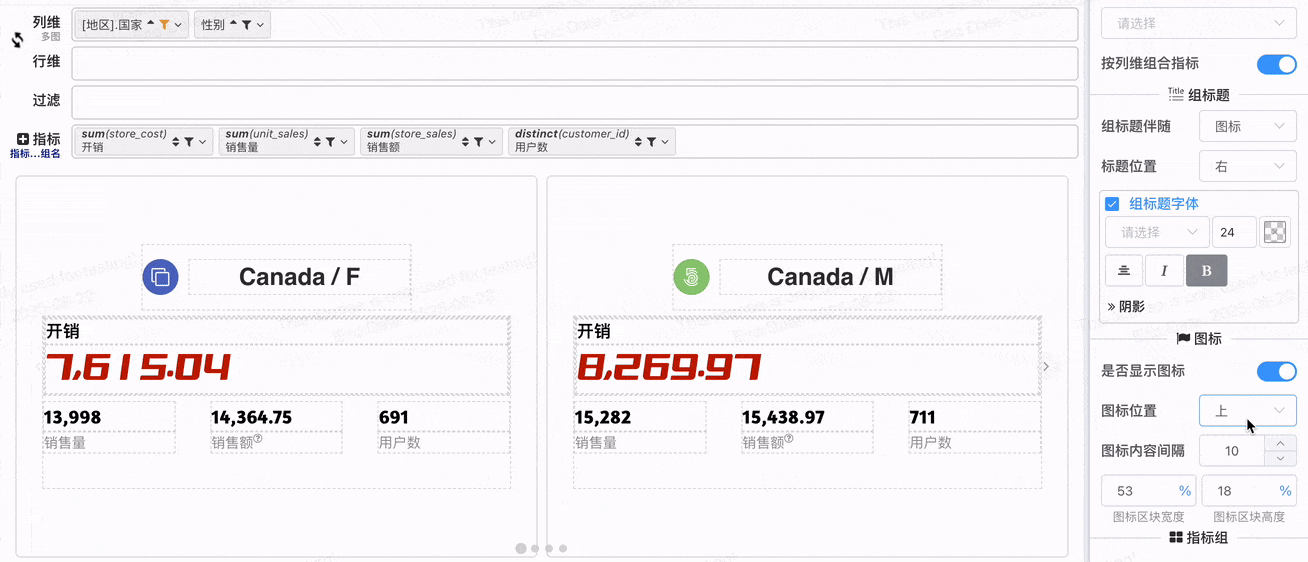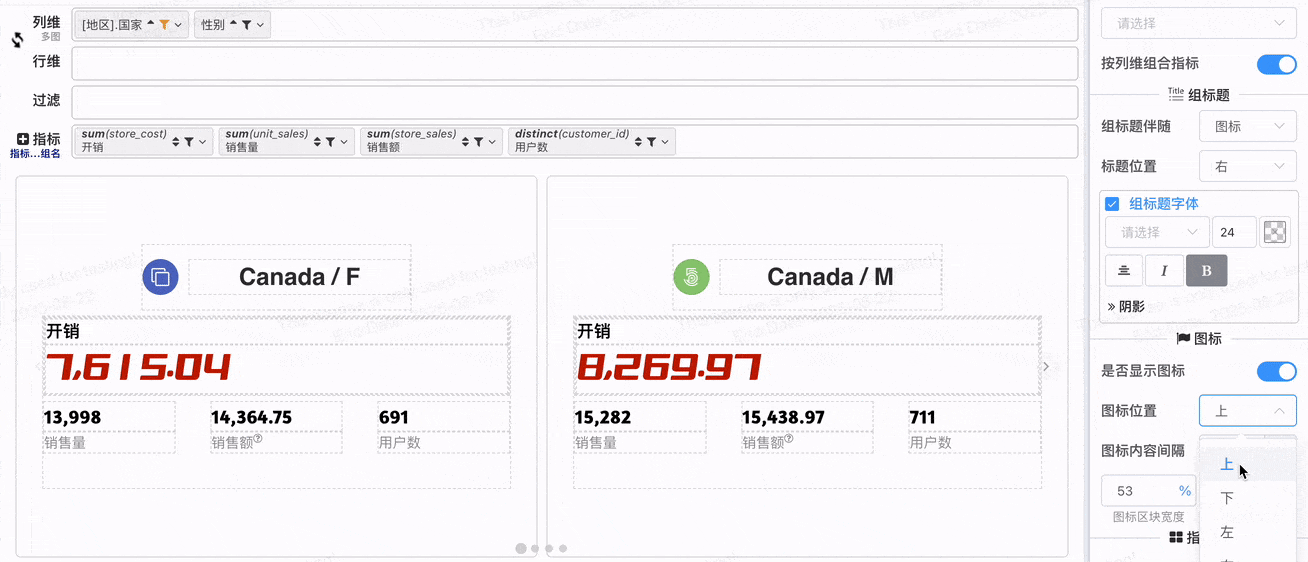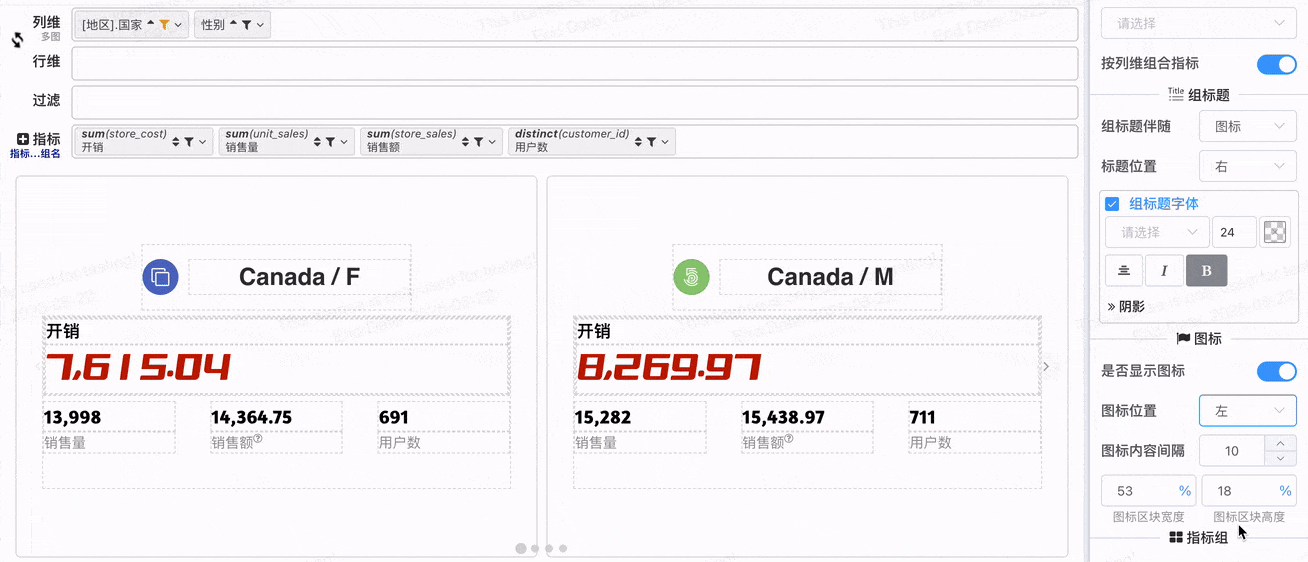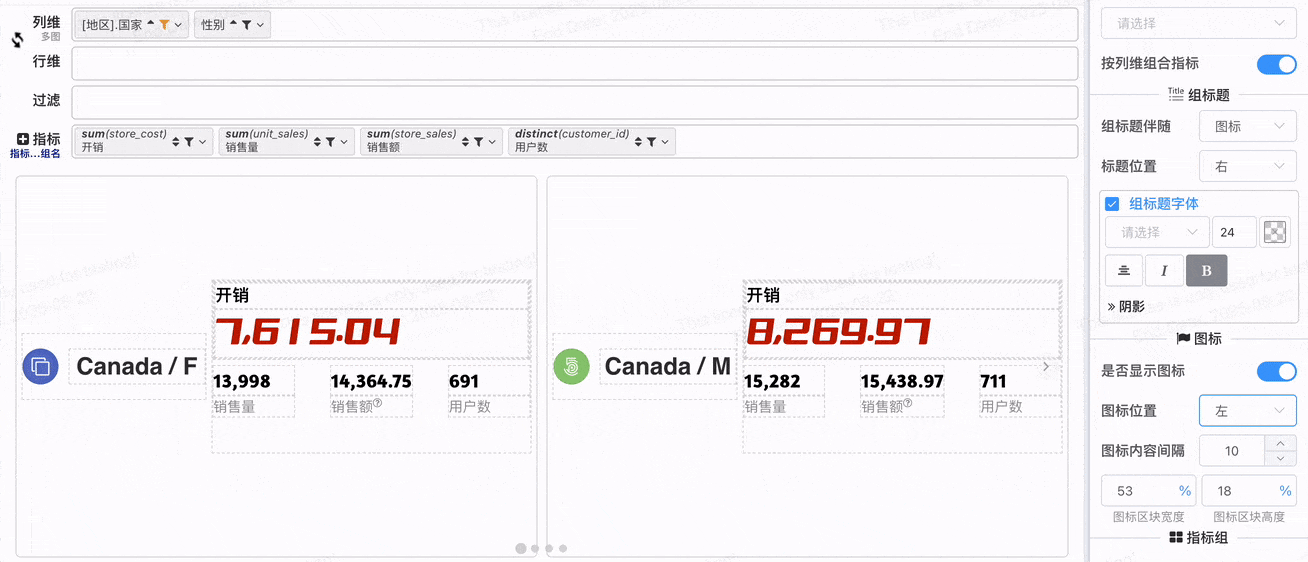
还可以配置
- 图标是否显示: 为了便于组标题布局,如果组标题伴随图标,即使图标不显示,图标区块也会存在
- 图表区块宽度与高度:图标区块位于上方配合高度配置,图标区块位于两边配合宽度配置
- 图标与内容间隔:用于配置图标与组标题间隔
- 图标选择、图标大小与圆角:在样式栏中配置
![]()
# 指标组
指标组为网格布局,你可以配置
- 网格行列数量
- 网格行列间距
- 指标组区块占卡片的整体宽、高

# 指标项
指标组中指标项统一配置
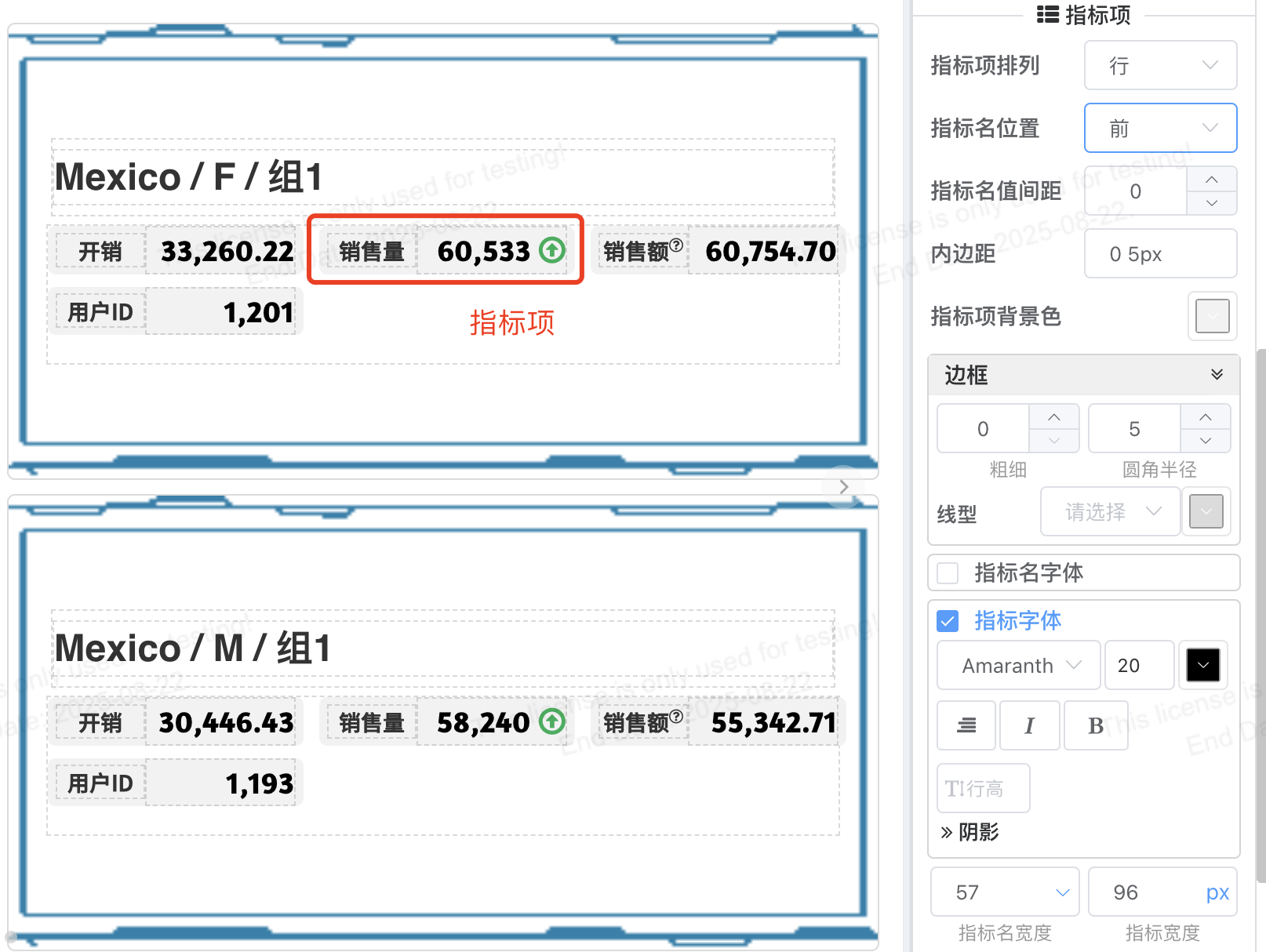

您可以配置指标项的
- 排列
- 指标名位置
- 指标名值间距
- 指标项目内边距
- 背景色
- 边框、圆角
- 指标名、指标值字体
- 按列排列时可以配置指标名、指标值宽度
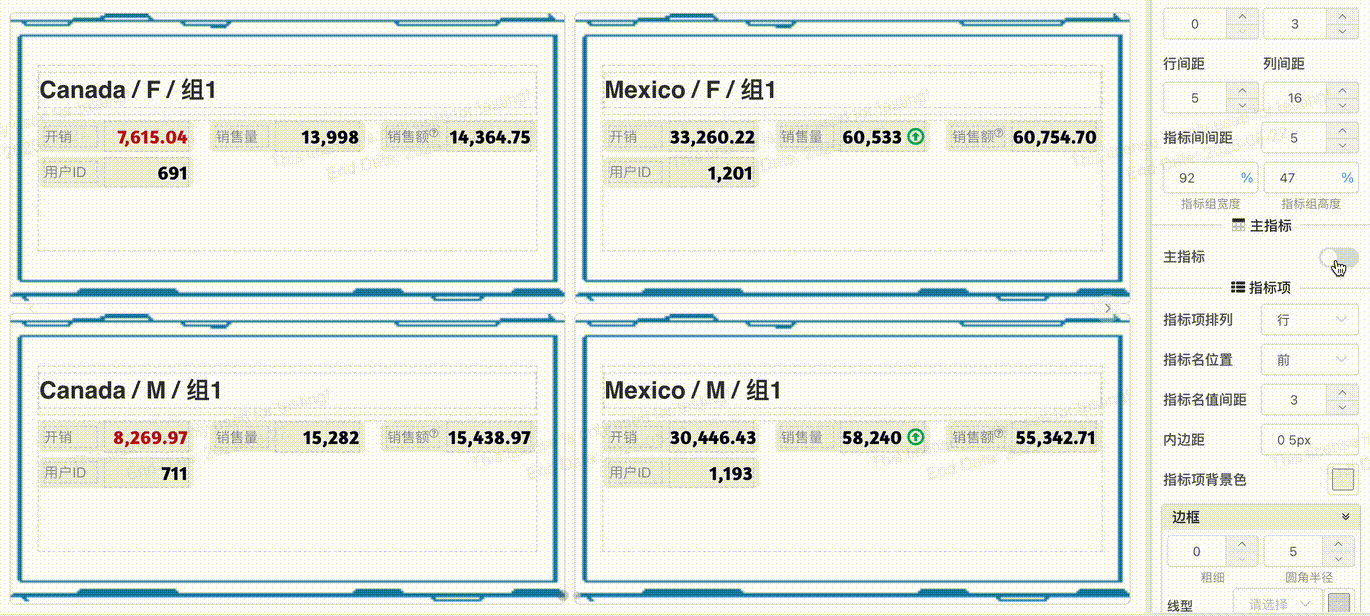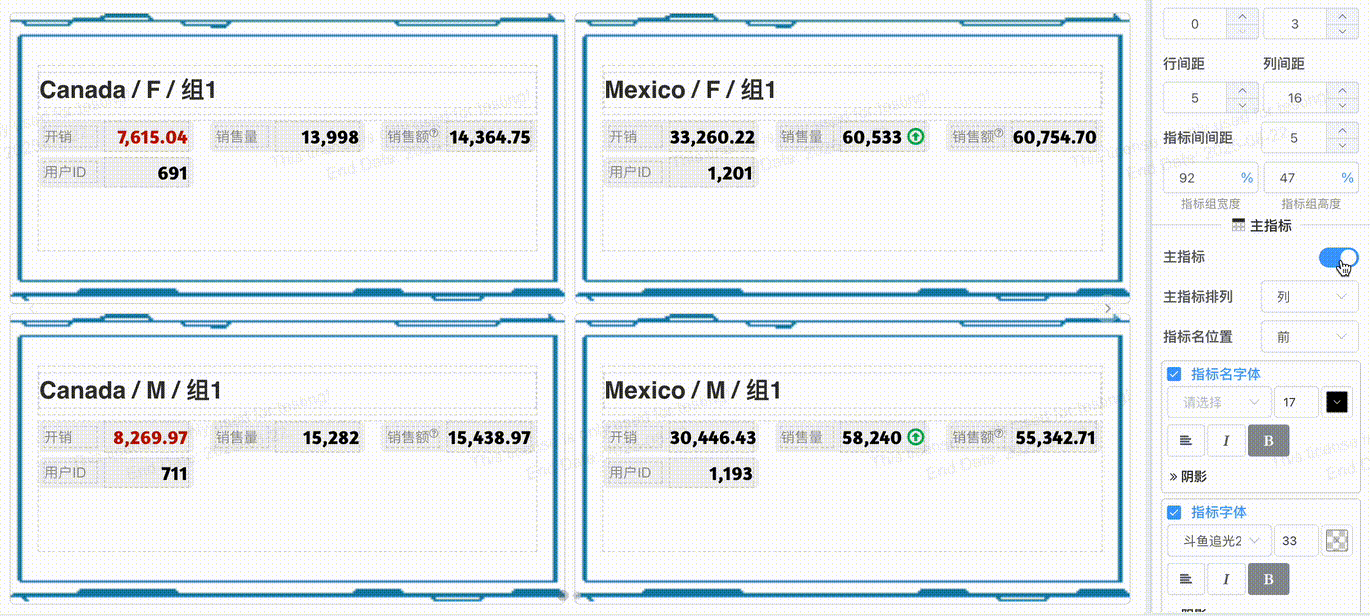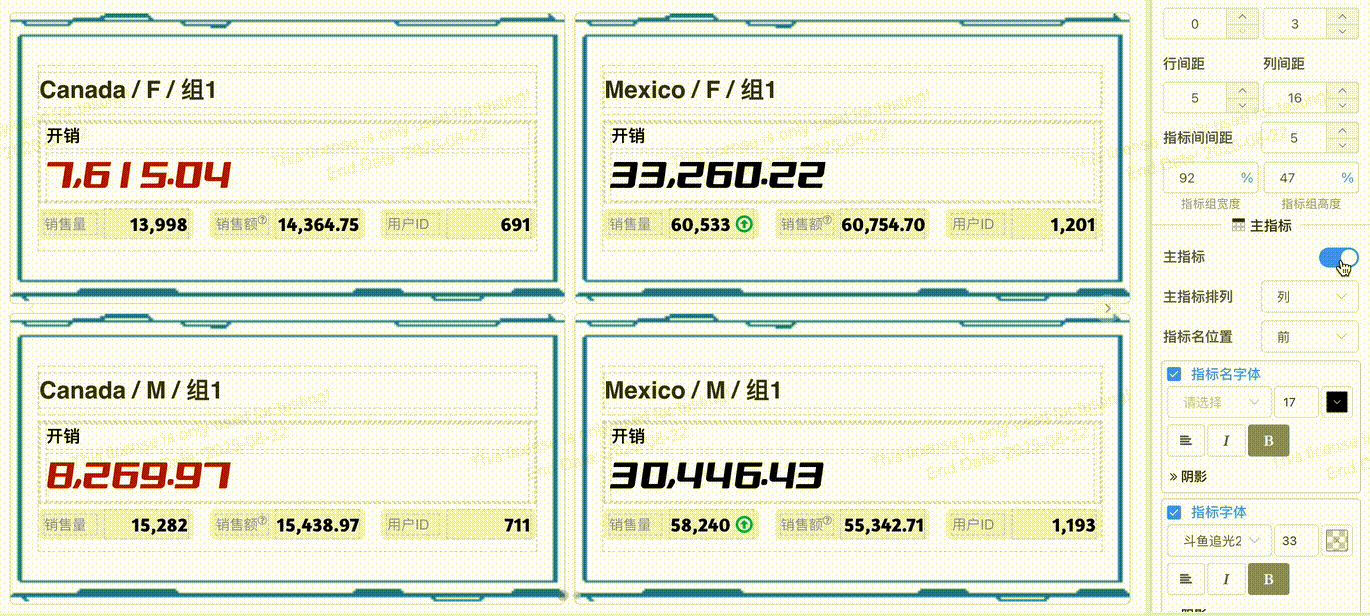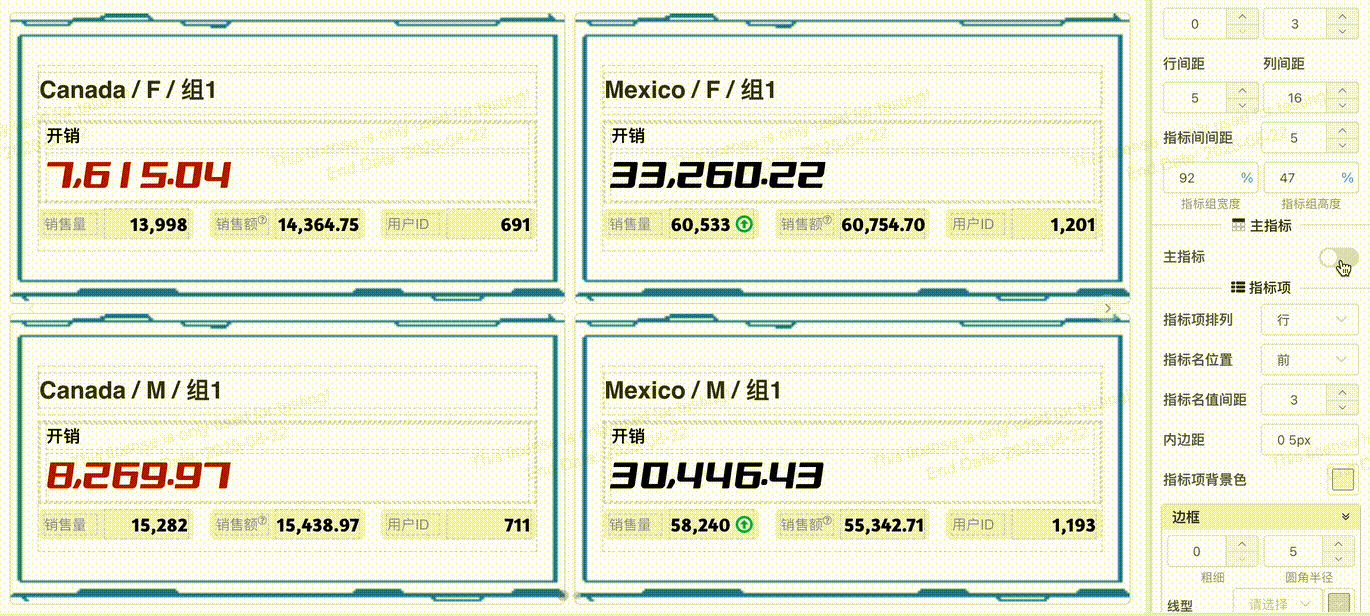
# 指标组合主从
开启主从指标,指标组内第一个指标会作为主指标, 主指标项目可以独立配置
# 一键应用主从指标模板
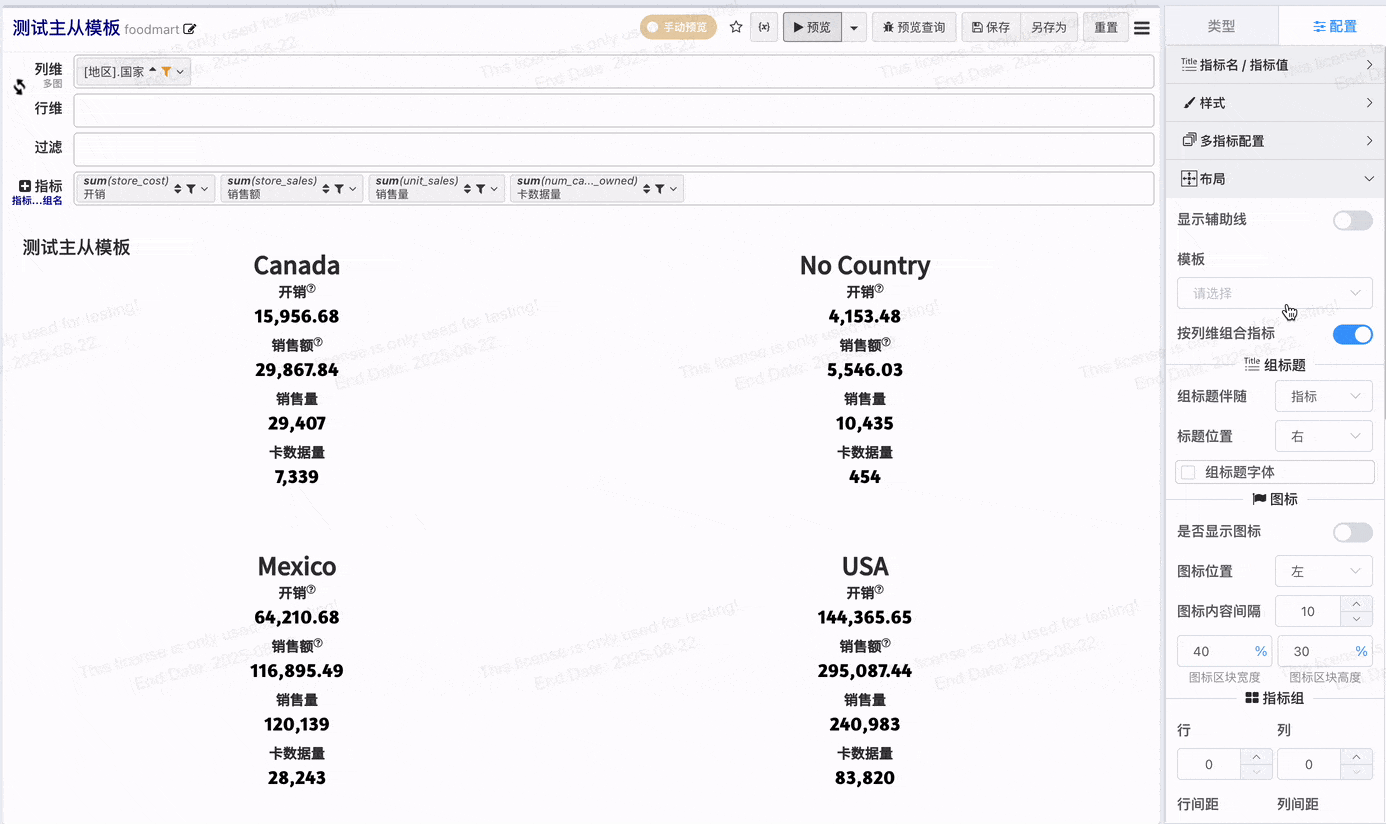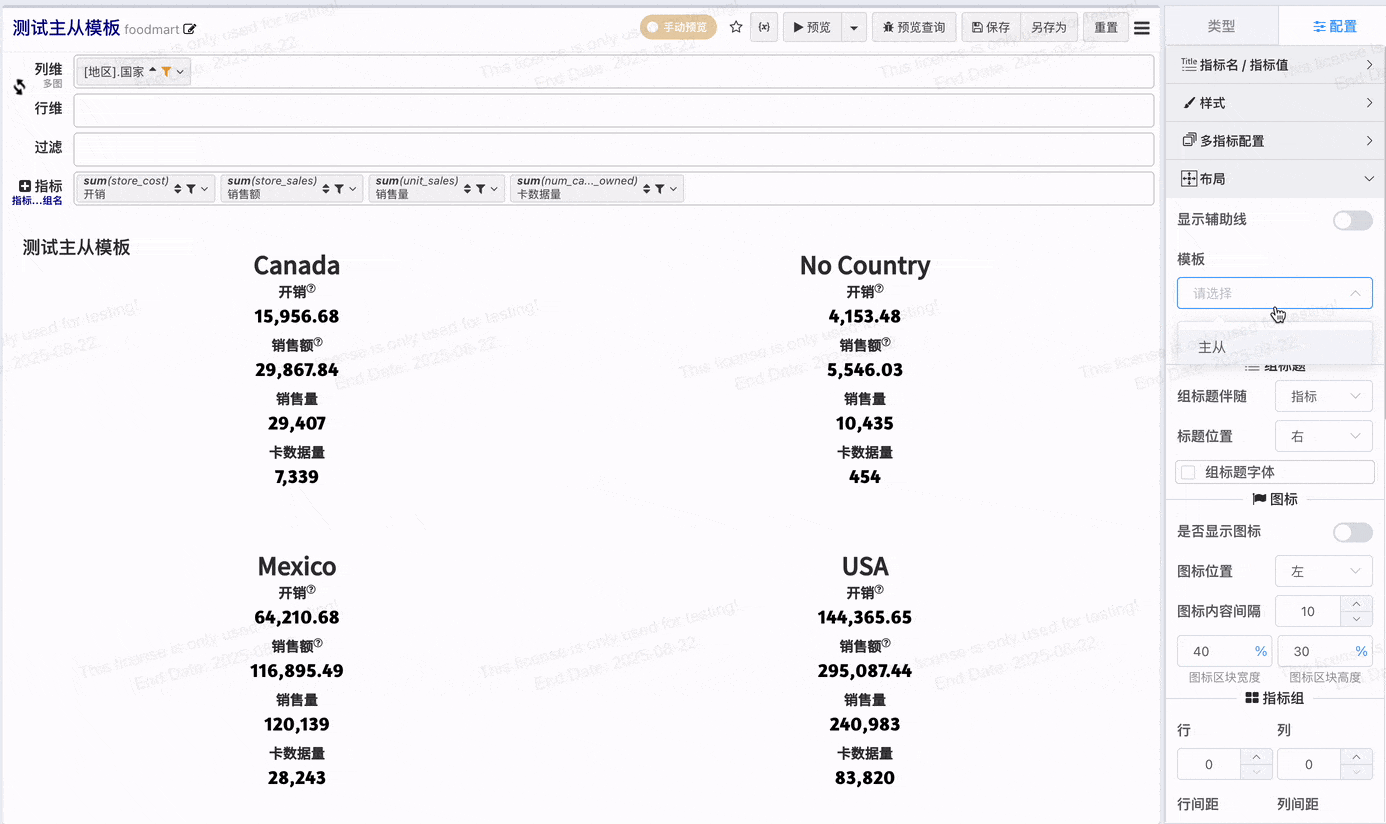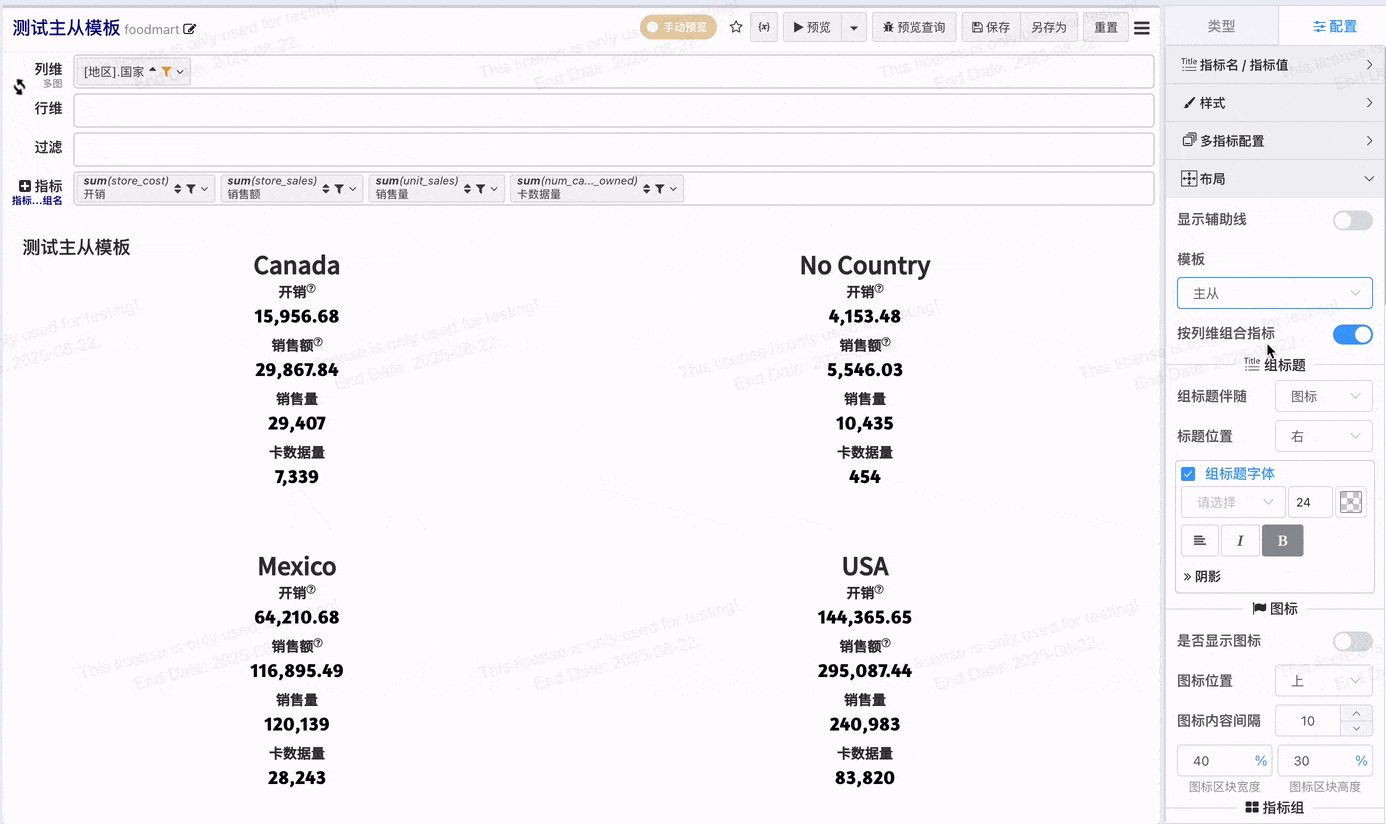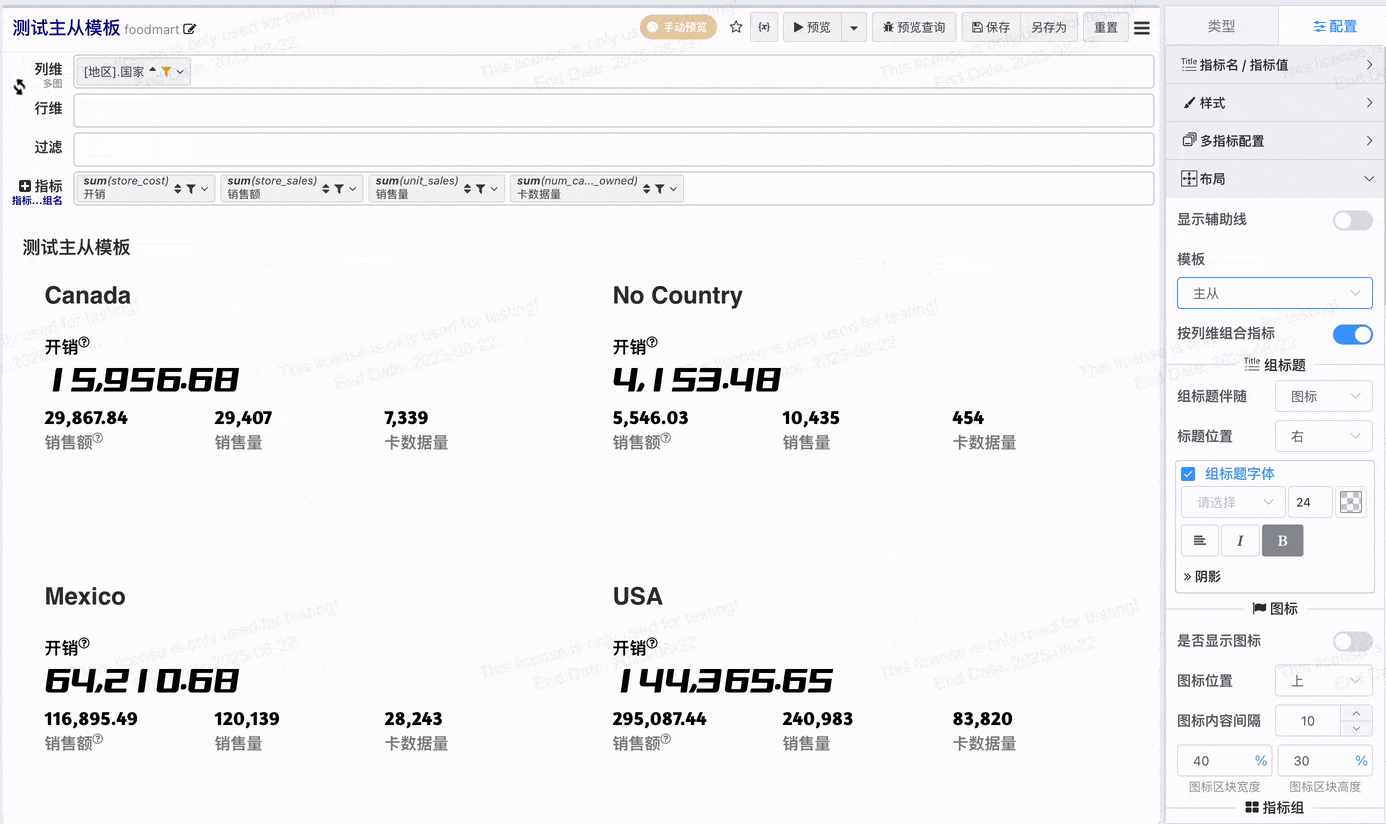
在开启指标分组的状态下,一键应用主从模板
# 矩形树图
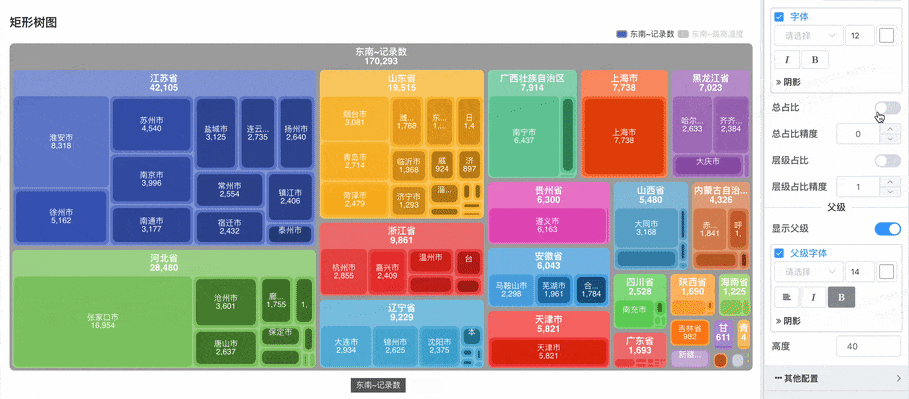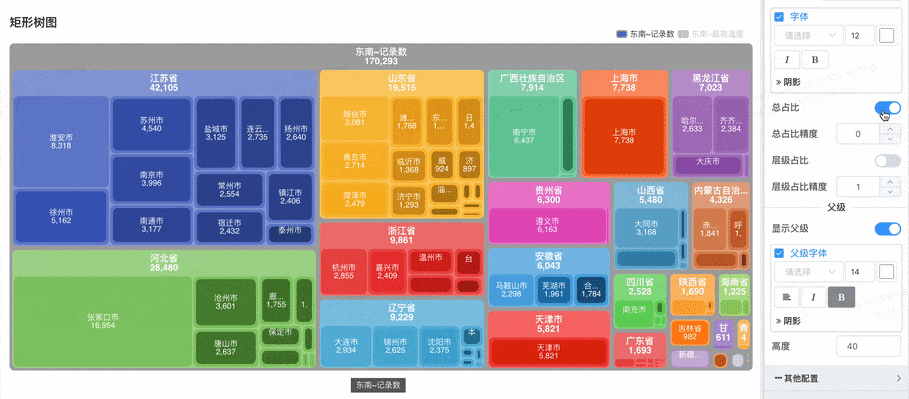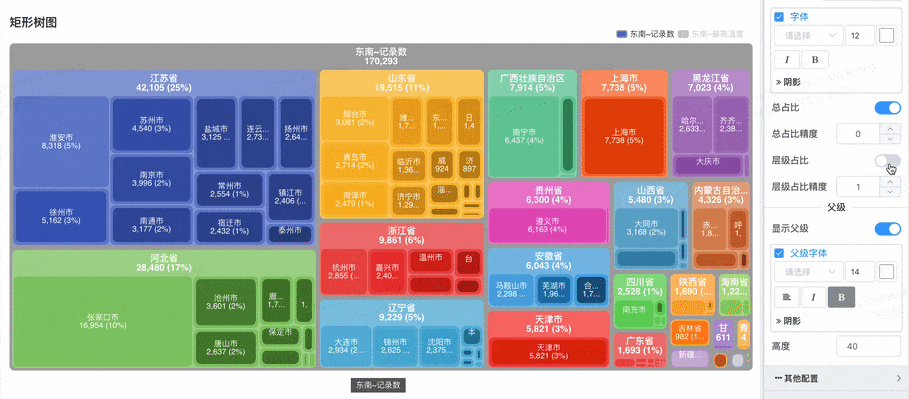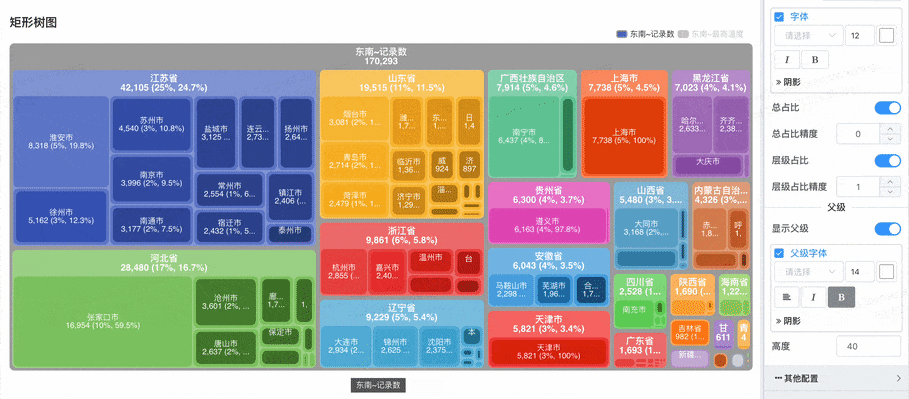
显示总占比与层级占比数字标签:
- 总占比:每个矩形区域会显示该项相对于所有数据总和的占比。
- 层级占比:每个子区域会显示该项相对于父级的占比。例如,在每一层级内,显示每个项目占父节点的百分比。
- 这些占比数字标签帮助用户 直观地了解数据的分布和层级关系。
- 优化了配置不显示数字标签时,也不显示项目名称的问题
# 柱线图
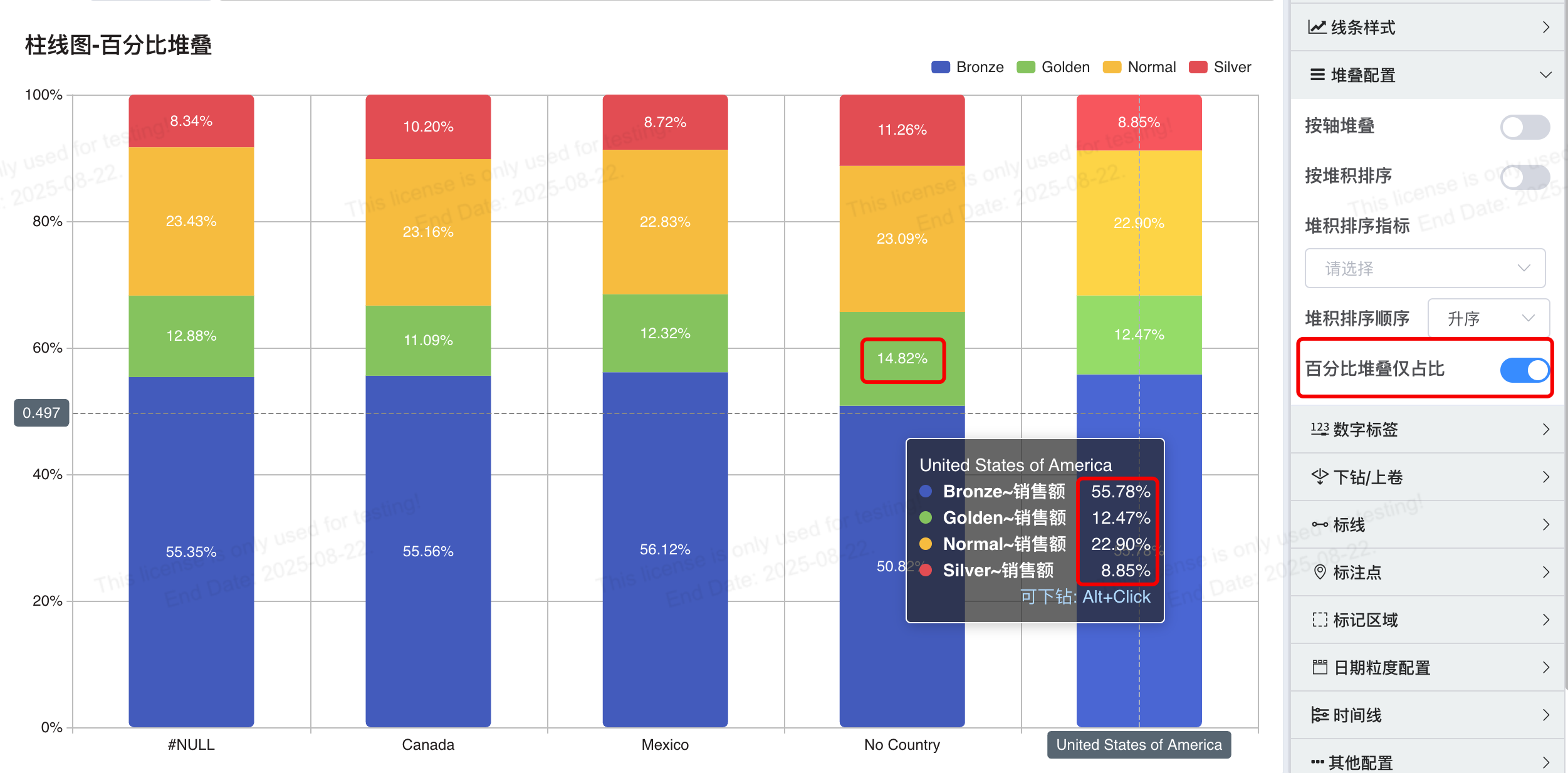
# 百分比堆叠配置仅显示百分比
只显示占比可以帮助用户专注于数据的相对比例,同时避免展示具体数据,满足那些对数据安全性有要求的场景。
# 配置拆分是否共享轴
当多个系列在不同的值轴下,数据的量级差异会使得可视化效果难以进行有效对比。但是如果数据都展示在同一个坐标轴下时,用户可以方便地在不同图表之间进行对比,快速看到每个系列的数据变化和相对差异。 例如,多个不同产品的销售趋势图,若共享相同的 值坐标轴,用户就能清晰地比较不同产品的变化程度和趋势。
共享坐标轴 有助于对比不同数据系列的 相对表现,如趋势、峰值、波动等。
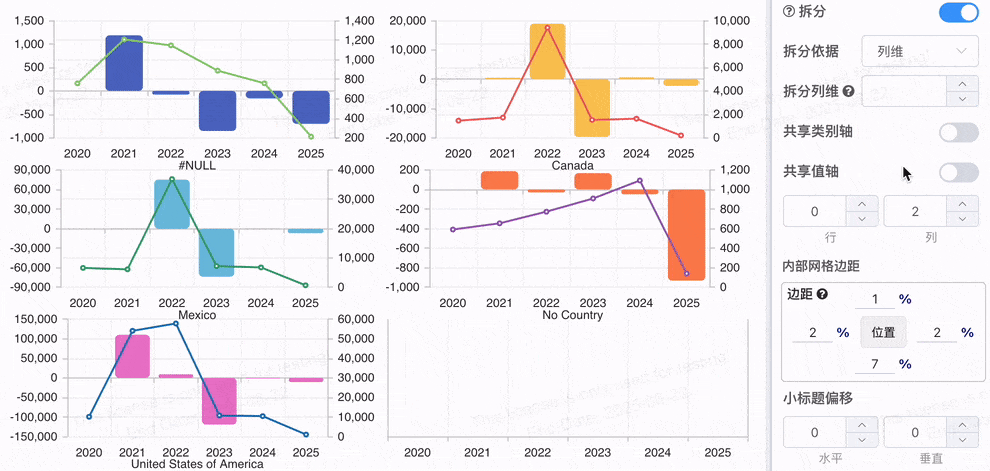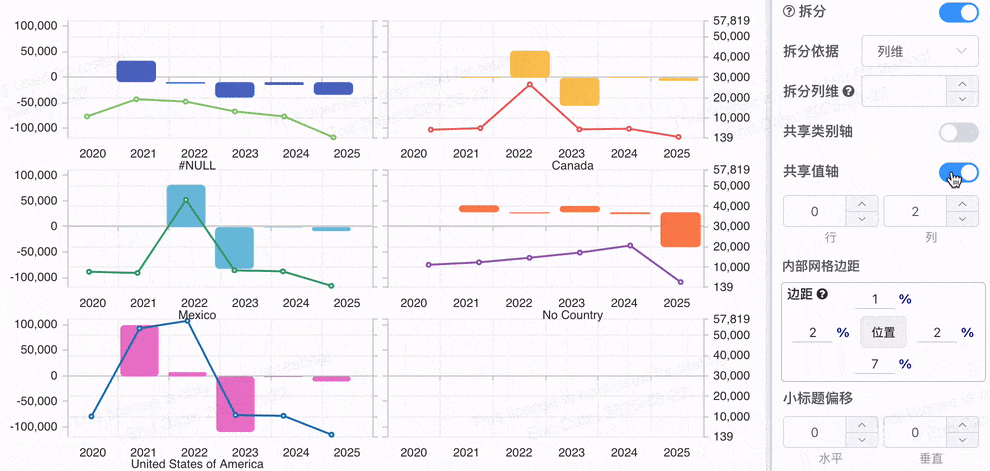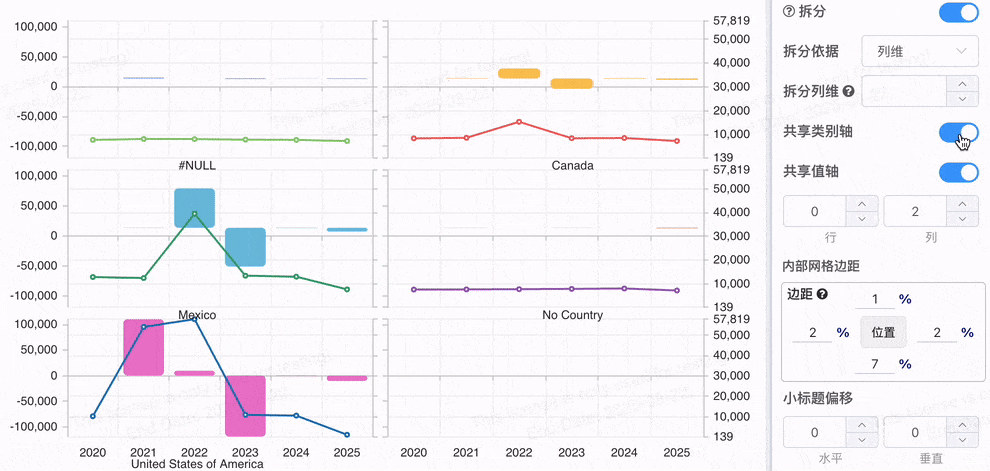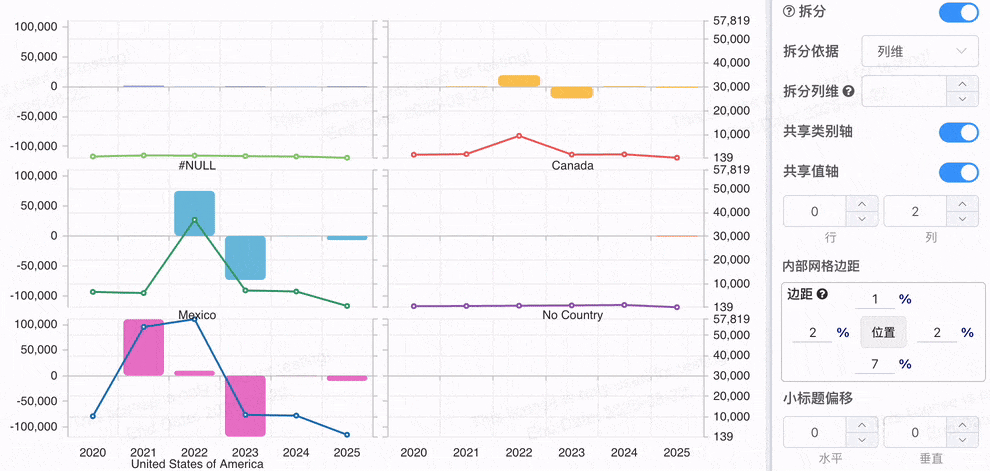
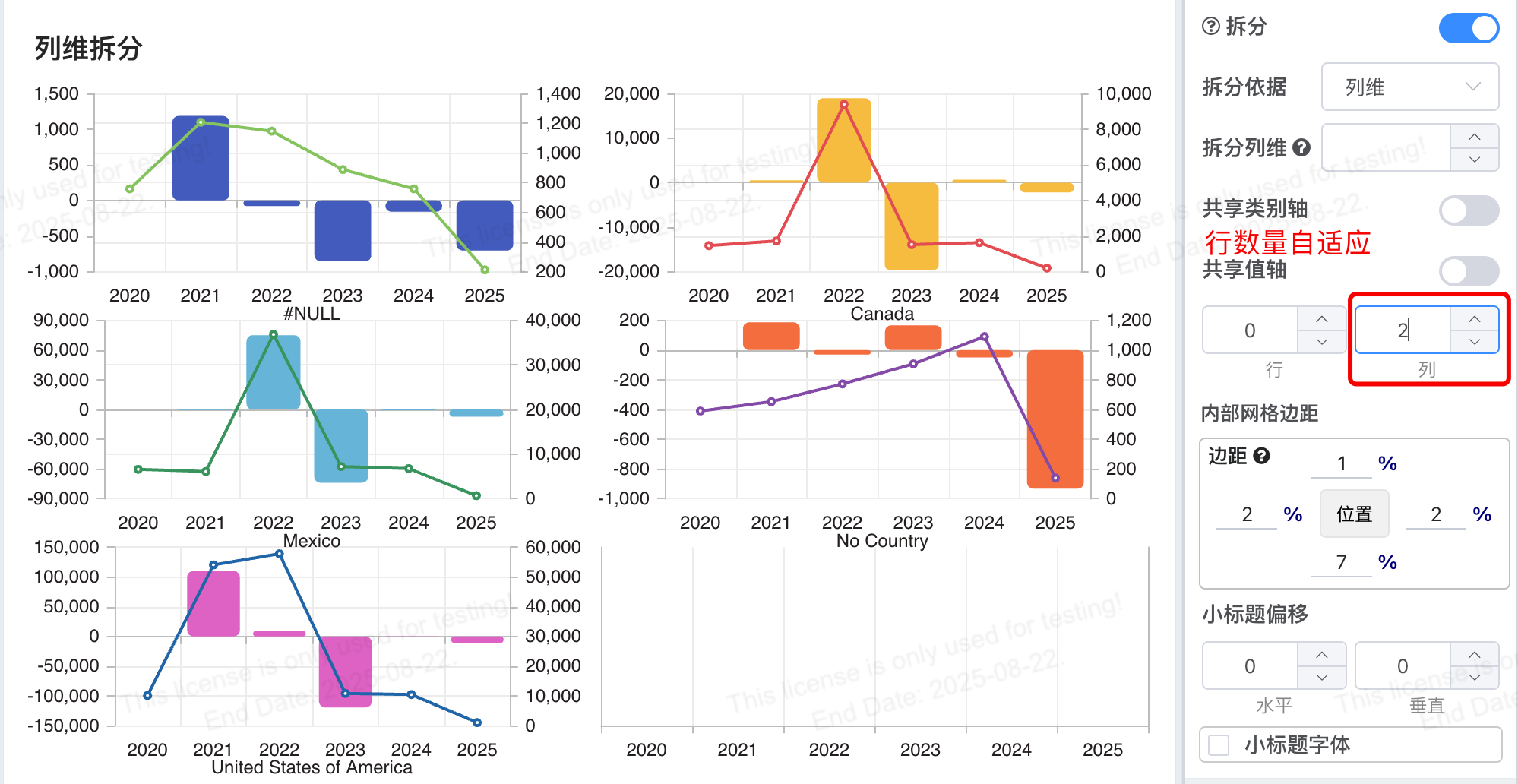
# 图表拆分为多图时的网格自动适应
在图表拆分为多个子图的场景中,网格行列数的配置得到了优化。以前,用户需要手动设置 行数 和 列数 来控制子图的排列,这样在子图数量发生变化时就需要重新调整网格配置。 现在,新增的功能使得用户只需要 设置其中一项(行数或列数),另外一项会根据子图数量 自动调整,无论是增加还是减少子图,都能够 自动适应。
使用场景:
动态适应: 当数据源不断变化,需要动态调整图表中的子图数量时,自动适应的网格能够保证图表的布局始终展示所有子图。
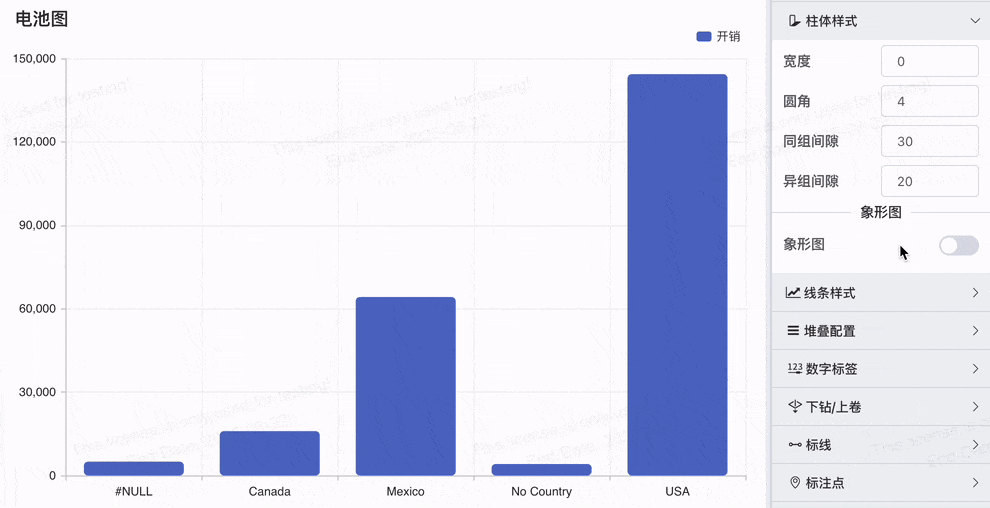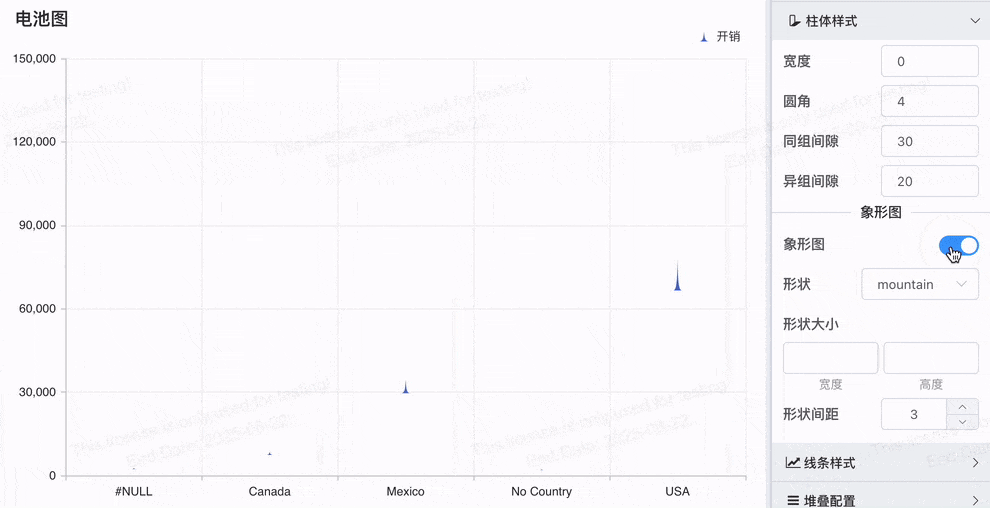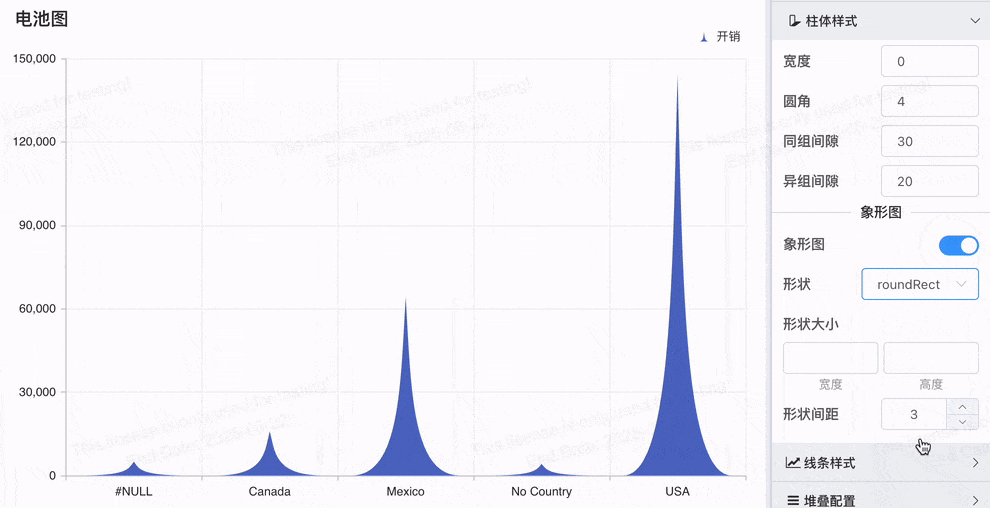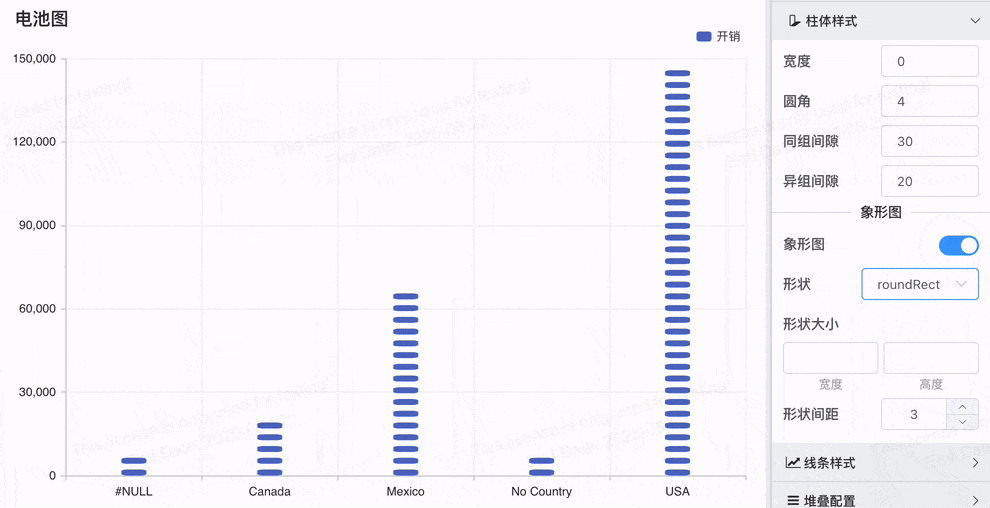
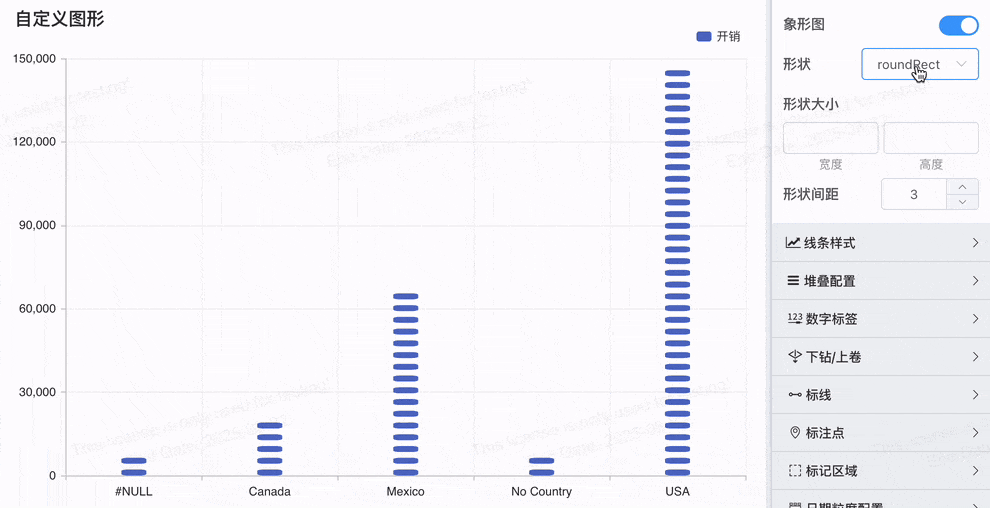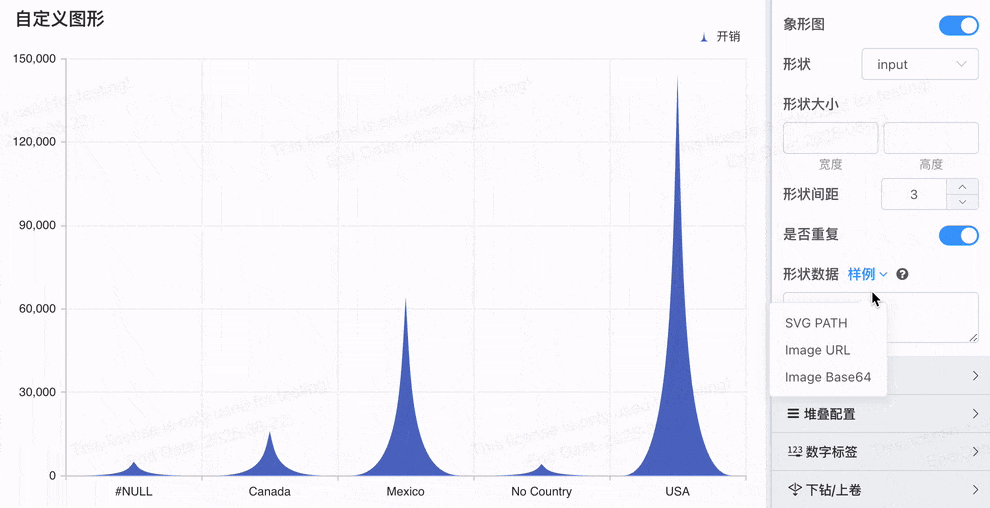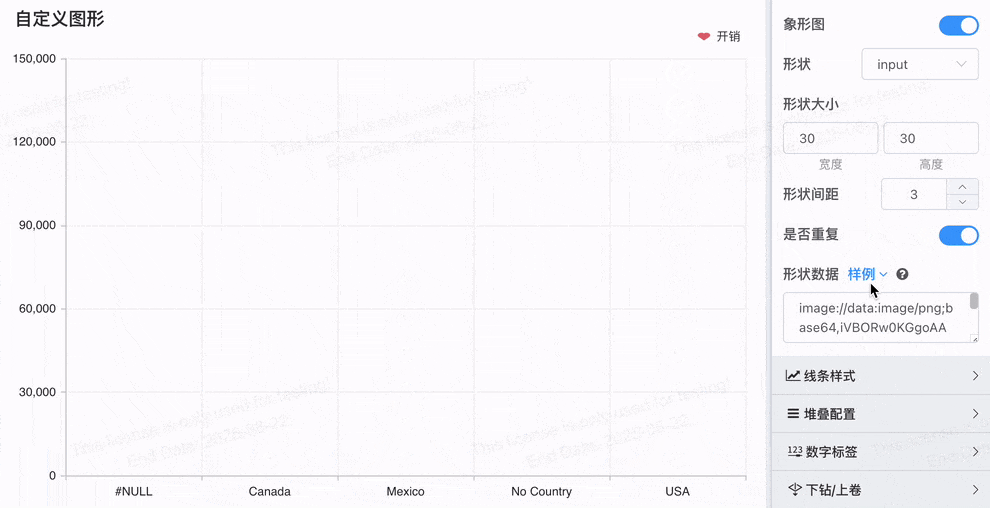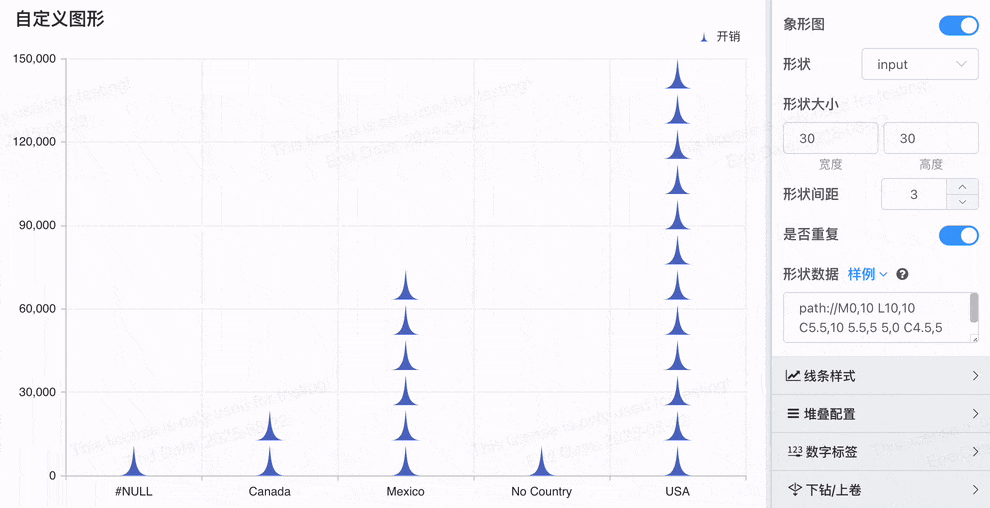
# 象形柱图,Symbol配置
象形图Symbol配置功能更加灵活和多样化,可以帮助用户根据实际业务需求定制化可视化效果
- 多形状支持:除了原来的山峰图形,新增的 'circle', 'rect', 'roundRect', 'triangle', 'diamond', 'pin', 'arrow' 等多种形状,使得用户可以根据需求选择最合适的图形进行数据展示。
- 电池图效果:通过 roundRect 形状,轻松实现电池图效果,展示电量、进度等数据。
- SVG Path 和自定义图片:支持自定义 SVG 路径 和 图片 URL / Base64,极大地提升了可视化的定制性和业务适配能力。
- 更丰富的量化展示:使得象形图不仅仅局限于简单的柱状展示,而能够通过多样化的图形和自定义图片,更加贴合实际业务需求,提供更具创意和互动性的可视化效果。
适用场景:
- 产品进度:展示产品进度、任务完成情况、项目进度等。
- 电量显示:展示设备的电池电量,或进度条等。
- 品牌标识:使用公司 logo 或图标,进行产品销量、市场占比等的展示。
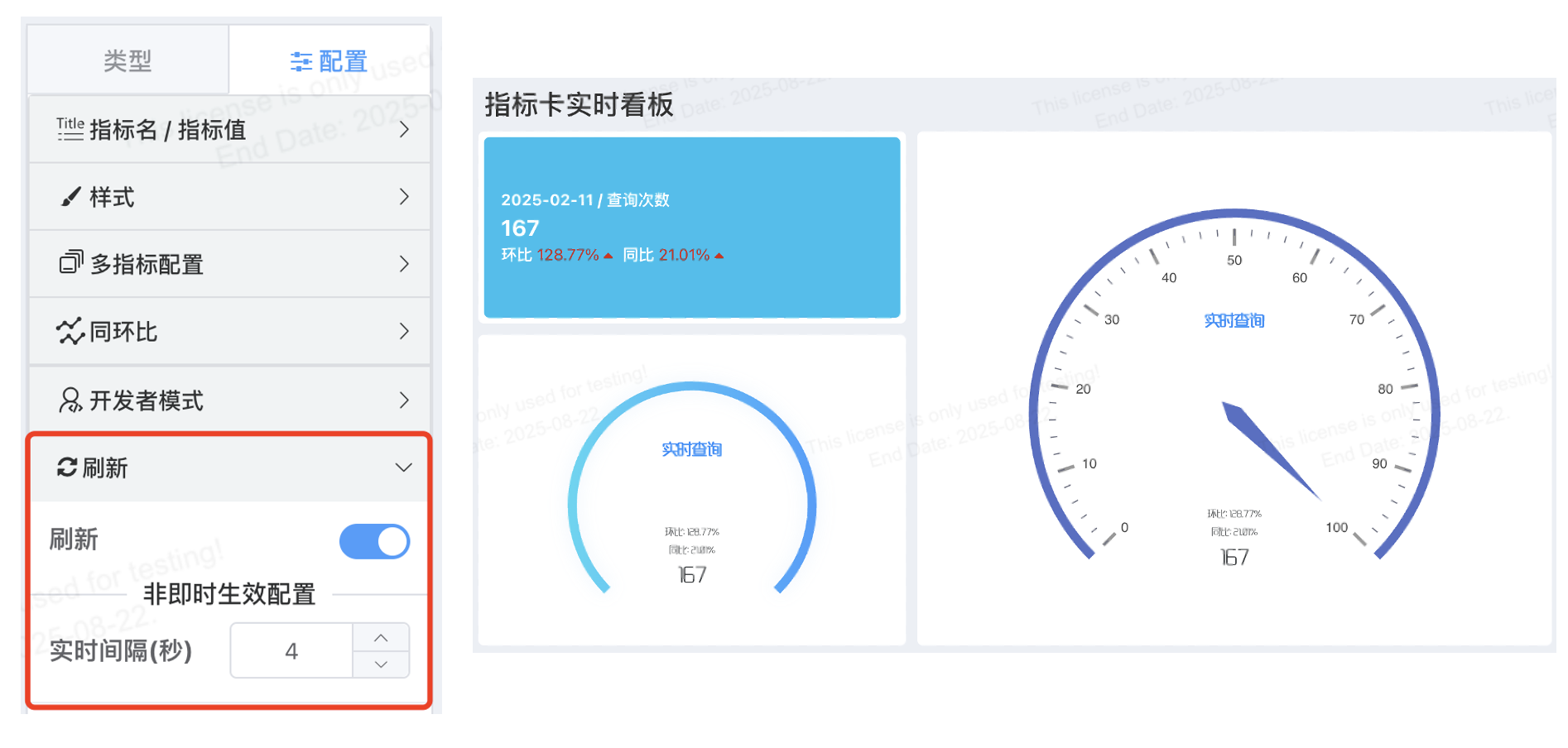
# 图表级刷新配置
增加图表级刷新配置,每个图表都能独立配置数据刷新间隔,配置优先级大于原有的数据集刷新间隔,两者同时配置时以图表级刷新事件为准。
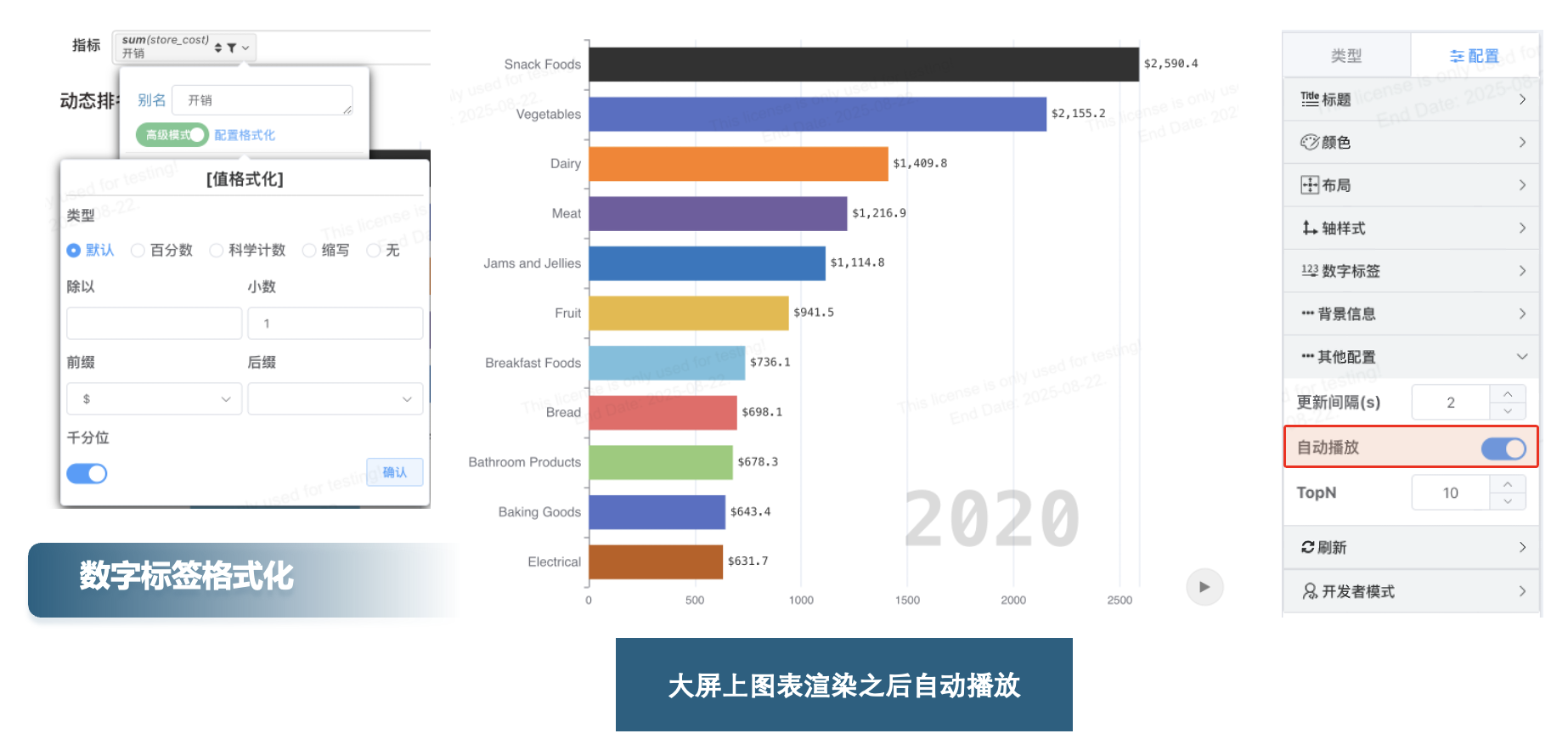
# 动态排行榜
动态排行榜优化:自动播放 & 数字格式化支持
# 自动播放
功能介绍:
动态排行榜新增 自动播放 配置,适用于 大屏展示 场景。在无需用户手动点击的情况下,排行榜可以在加载完成后 自动开始播放。
# 数字标签使用指标配置格式化
功能介绍: 动态排行榜的数字标签 支持使用指标配置的格式化,确保数值显示符合用户的习惯和需求。动态变化的数字将根据 通用的格式化配置 进行展示,提升可读性。
使用场景:
- 金融数据展示:支持千分位分隔、货币符号(¥、$)等格式,确保财务数据直观易读。
- 销售/市场分析:百分比(%)、小数位数控制等格式,让增长率、市场份额等数据更加清晰。
- 流量监控:支持 K、M、B 缩写,便于大数值展示(如 10K、1.2M)。
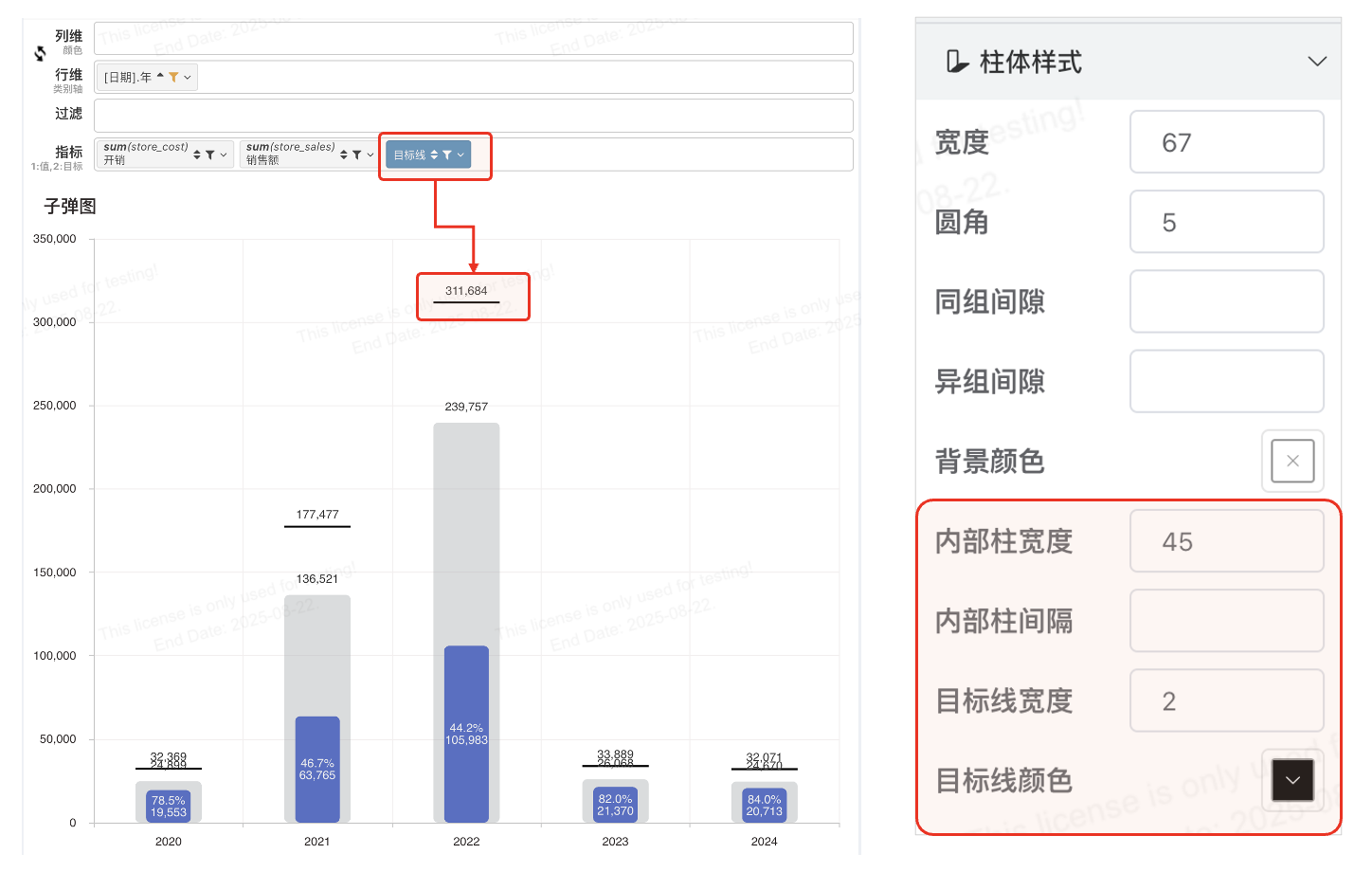
# 子弹图配置项
增加目标线绘制 进度槽背景色、实际值宽度、目标线颜色与宽度
# 词云新增分词配置
为进一步提升 词云图 的灵活性和可视化效果,新增了 分词配置 功能,允许将组合的关键词拆分为 独立关键词。此功能不仅提高了词云图的精确性,还可以根据 维度分组 和 项目分词 配置,灵活处理不同的数据格式,生成更具分析价值的词云。
1. 维度分词:
类别维度与产品名称维度拆分:在组合模式下,某些字段可能会组合成一个关键词,但在展示时,我们希望将其拆分为多个独立的关键词。例如:
- 组合关键词:
办公用品~尺子 - 拆分后的关键词:
办公用品和尺子
这种功能适用于数据源中存在多个维度组合时,需要将多个维度的词汇拆分开来显示。
示例:
- 原始记录:
办公用品~尺子 - 拆分后:
办公用品,尺子
- 组合关键词:
2. 项目分词:
产品名称拆分:对于产品名称字段,如
惠普 打印机,希望将产品名称拆分为两个独立的关键词:惠普和打印机。默认分词规则:默认情况下,项目分词规则为 逗号、空格、Tab,可以通过配置自定义分词正则表达式。
示例:
- 原始记录:
惠普 打印机 - 拆分后:
惠普,打印机
- 原始记录:
3. 可配置分词正则表达式:
灵活的分词配置:用户可以根据实际需求,自定义分词规则,支持灵活配置不同的分隔符或正则表达式。比如:
- 默认使用 逗号、空格、Tab 来分隔关键词。
- 用户也可以自定义正则表达式,例如支持其他特殊符号或字符的分词。
自定义分词示例:
- 默认:
惠普 打印机→ 拆分为惠普和打印机 - 自定义规则:
正则表达式分割符,比如根据~或;等特殊符号进行拆分。

# 复杂报表
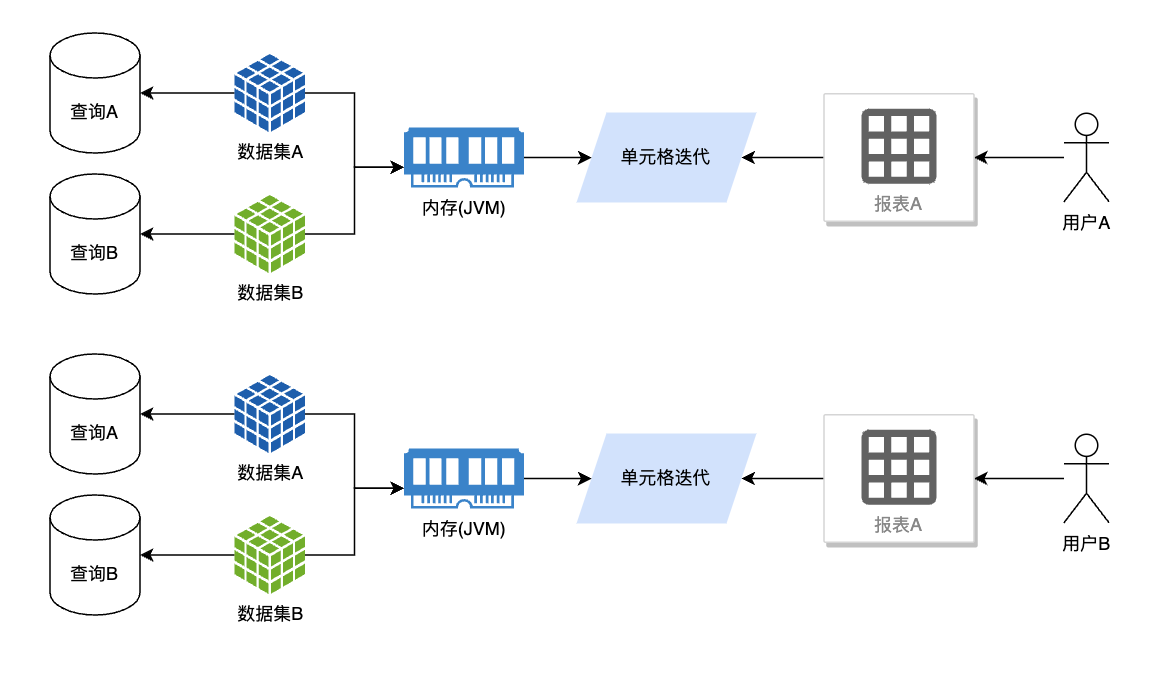
# 重要 查询缓存Caffeine
没有缓存的情况下每次查询单独查询、加载数据集
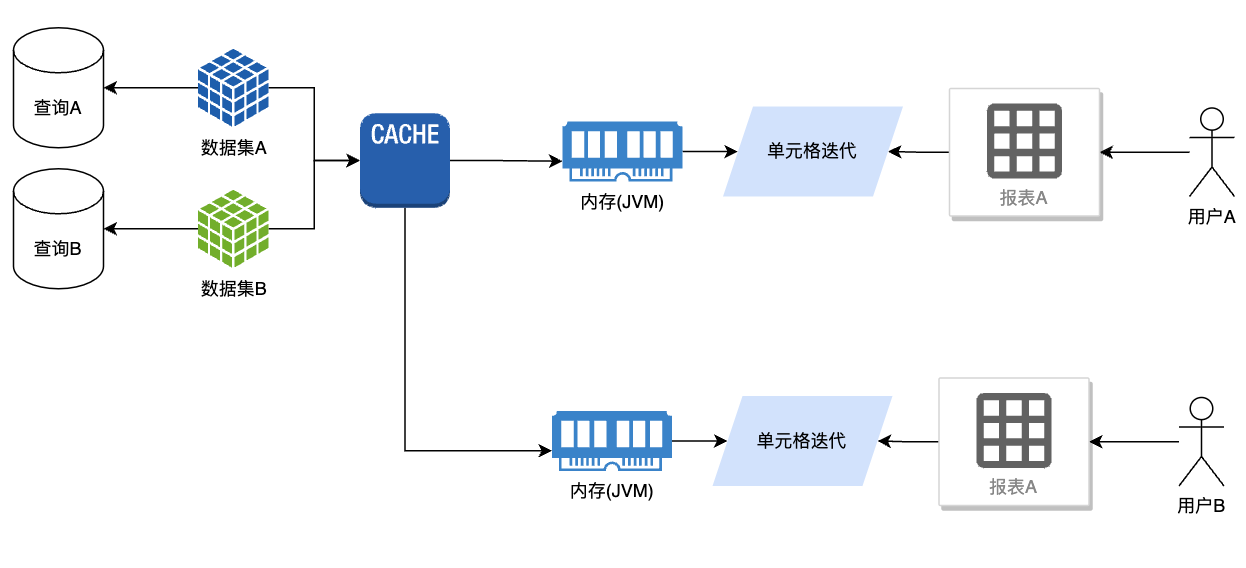
增加缓存之后, 第二次查询直接读取Cache中已有的数据,内存中也不需要重复保存多份数据集
# 表达式编辑坐标拾取状态提示
在复杂报表的表达式编辑过程中,用户可以在表达式中插入单元格坐标。这种功能对于 动态报表设计 或 公式编辑 非常重要,它能够帮助用户通过点击单元格来获取坐标并将其插入到公式中。 为了提升用户体验,本版本新增了 明确的单元格拾取提示,让用户能够清楚知道当前处于 单元格拾取状态,以及如何正确地切换目标单元格编辑状态。

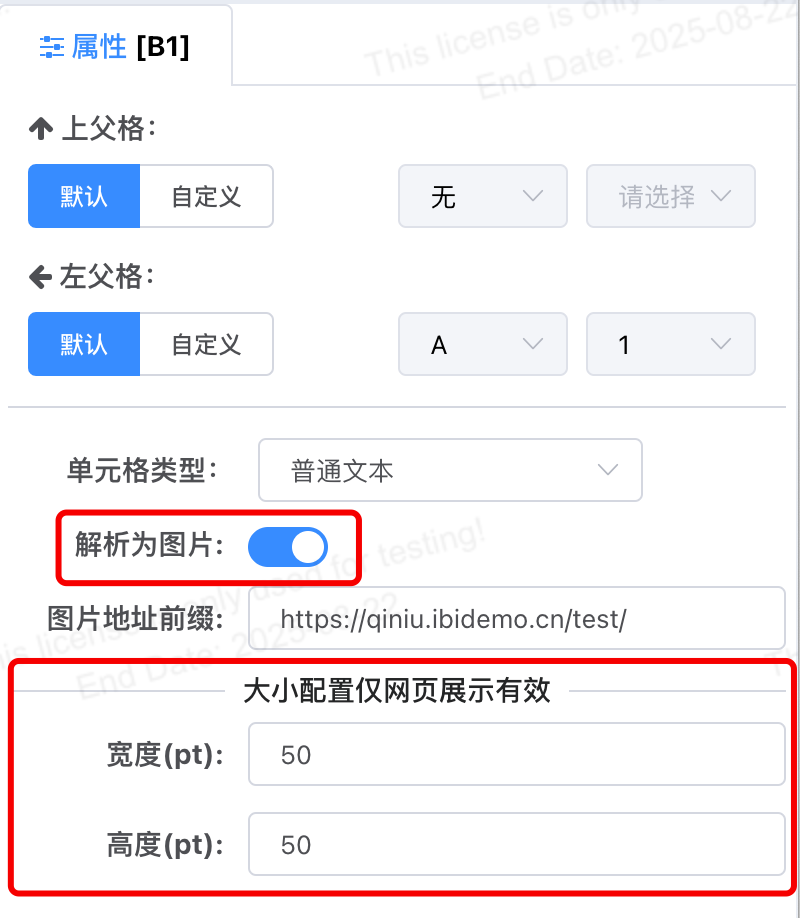
# 图片大小配置
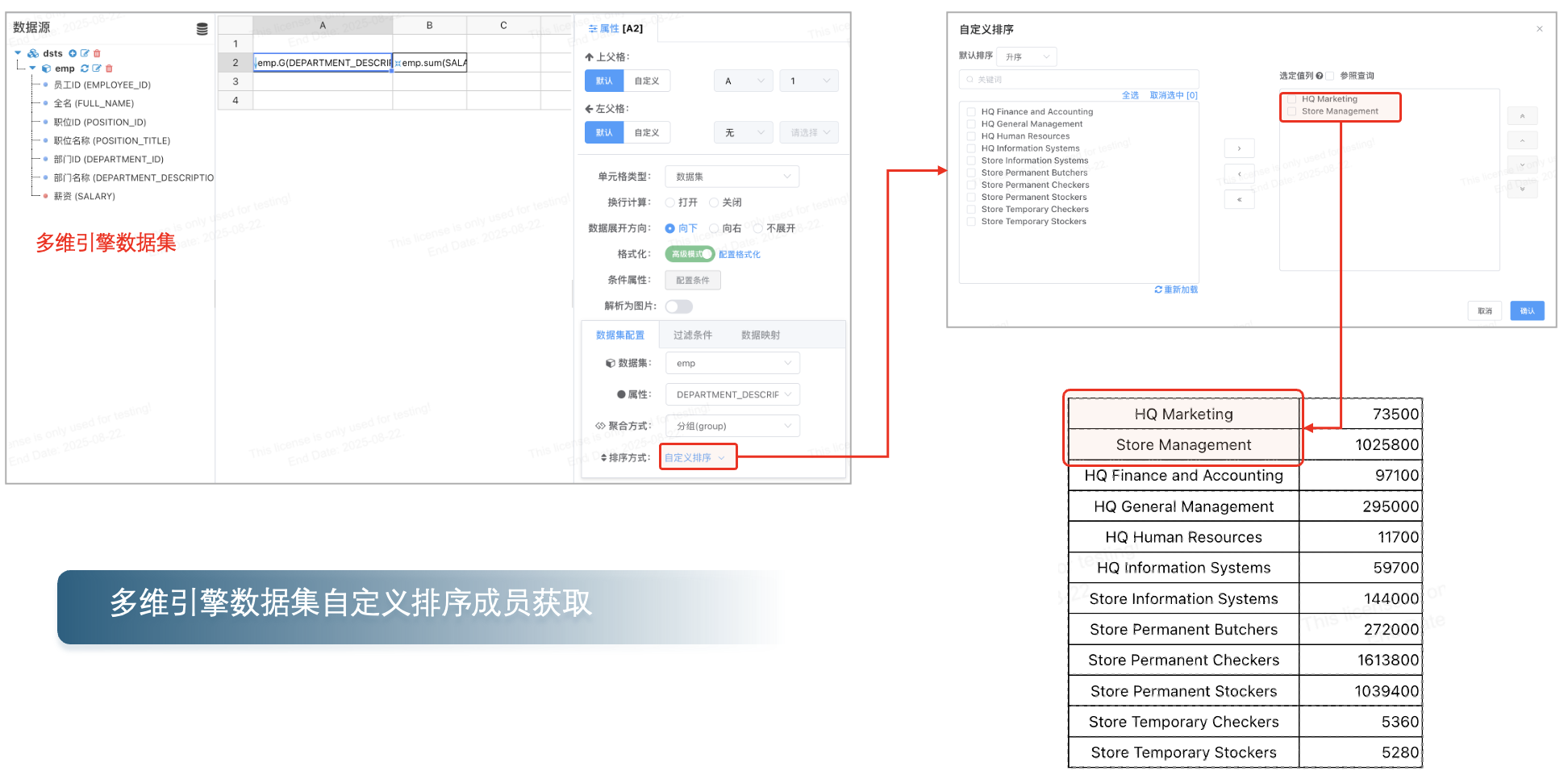
# 多维引擎数据集自定义排序成员获取
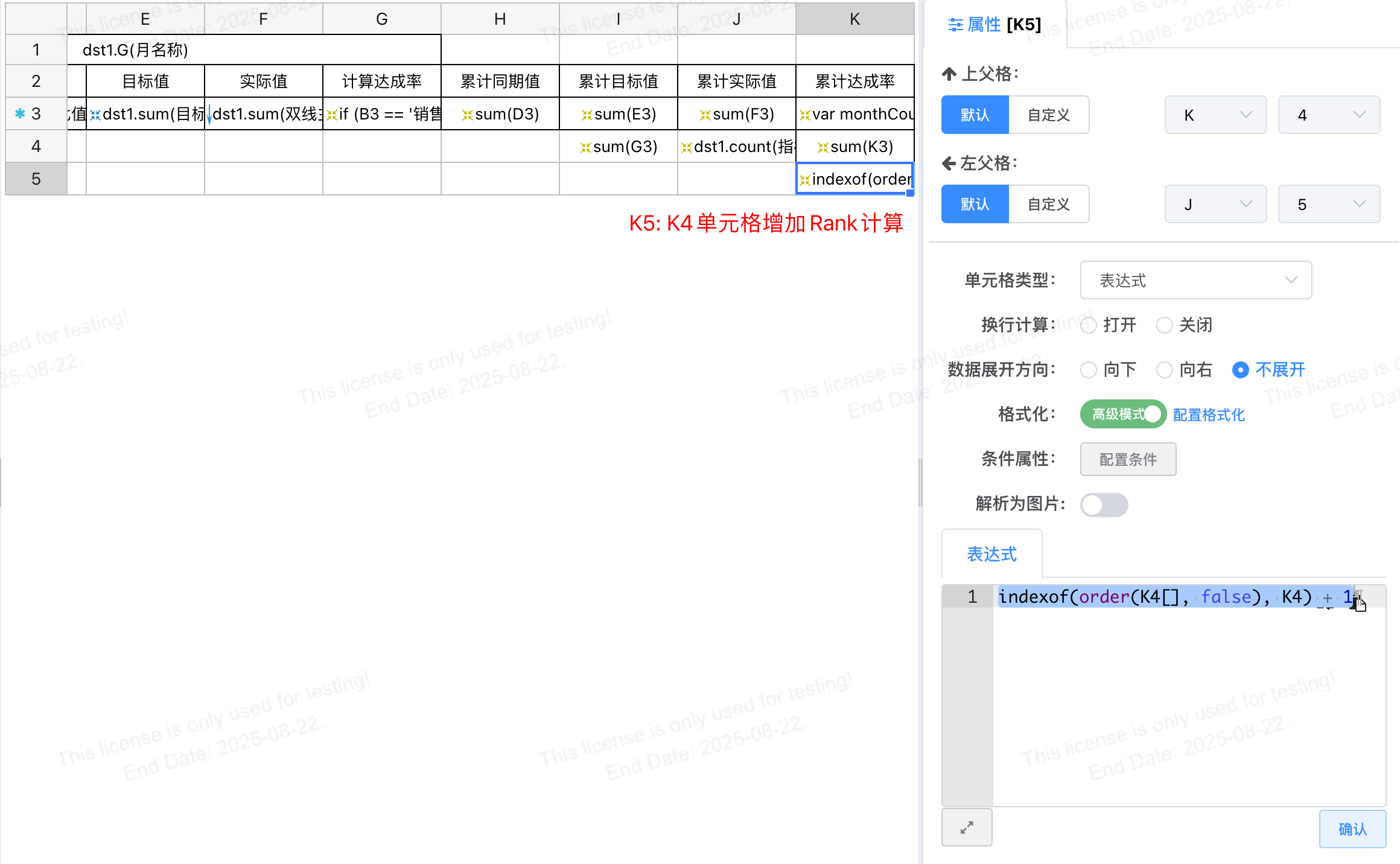
# IndexOf 函数支持数组判断,可用于rank计算
indexof(order(K4[], false), K4) + 1
1
解释:
- K4[]: 为取所有K4单元格的元素
- order(K4[], false): 对所有K4元素进行降序排列, 返回降序数组
- indexof(order(K4[], false), K4): 返回当前K4在降序所有的位置从0开始计数, 所以后面要加1
# [优化] 复杂报表数值格式化
0.x显示前面的0,toBigDecimal整数不要带小数,小数不要出现多余的小数位
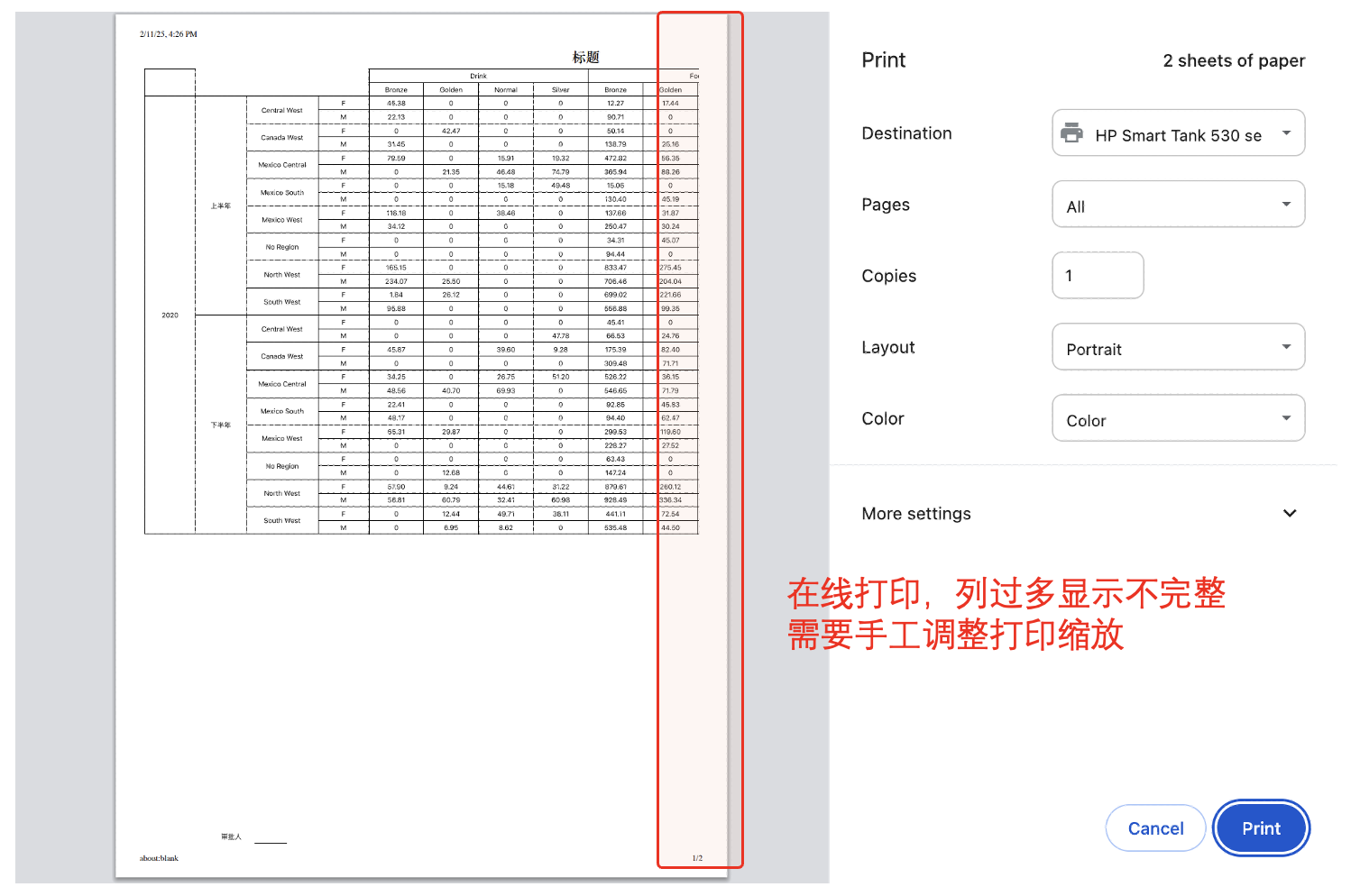
# html在线打印列过多时自动缩放适应页面
调用浏览器打印功能在线打印,列过多显示不完整需要手工调整打印缩放
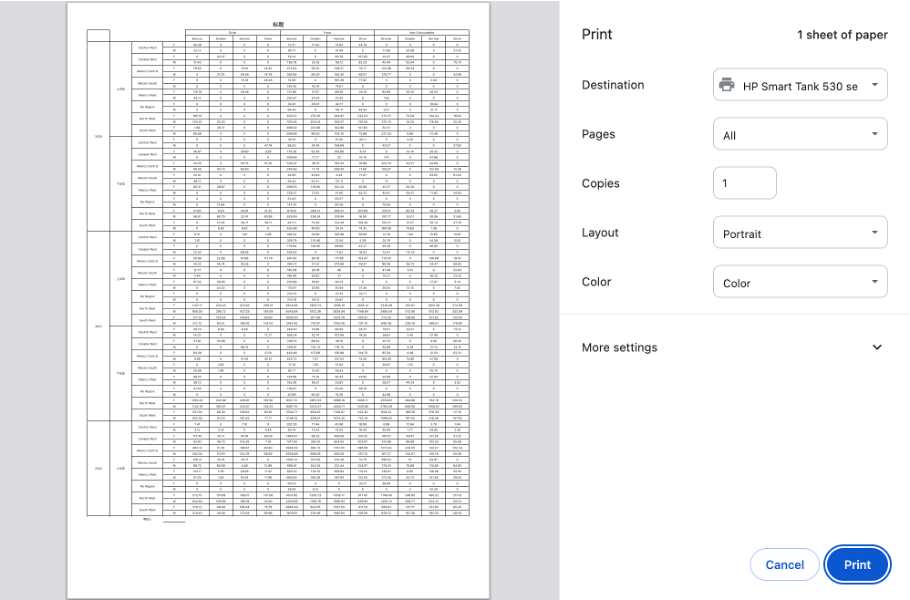
自动缩放, 报表生成时缩放字体与行高等,并重新计算分页,实现一键打印宽表
# 复杂报表导出PDF
- 表格列过多时支持pdf生成缩放
- 缩放后重新分页计算
# 复杂报表导出Word文档
- 表格列过多时支持PDF生成缩放
- 缩放后重新分页计算
# 打印相关
# 纸张设定
- 纸张方向设定
- 打印边距配置
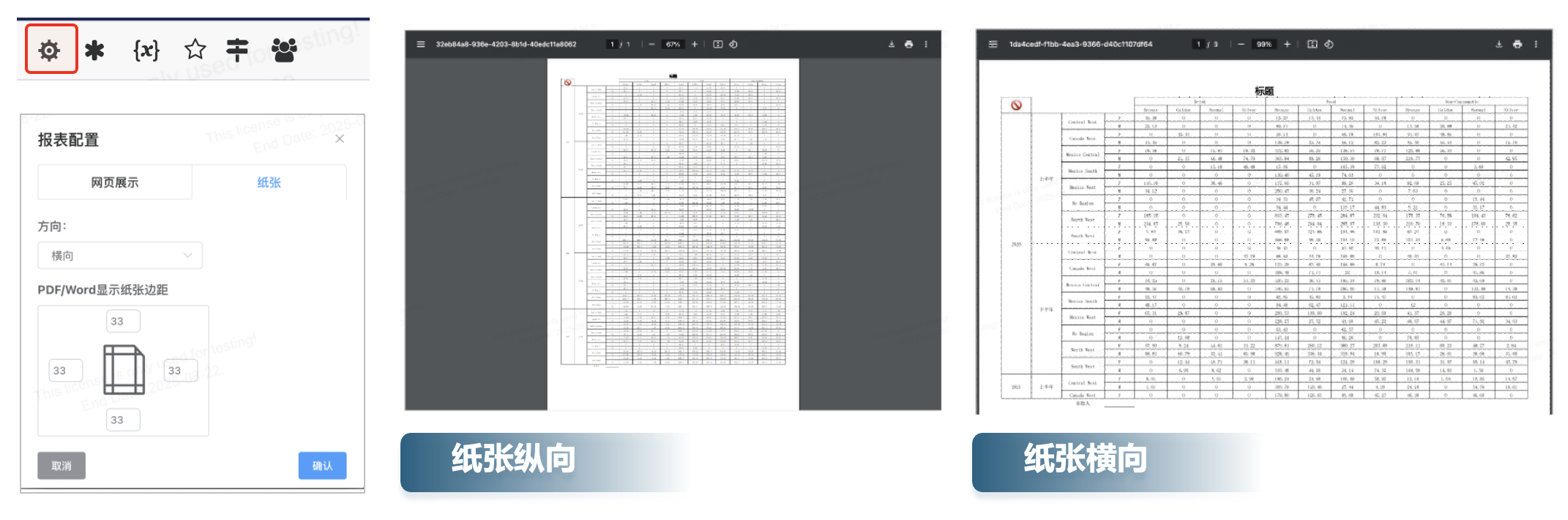
# 打印预览

# 看板
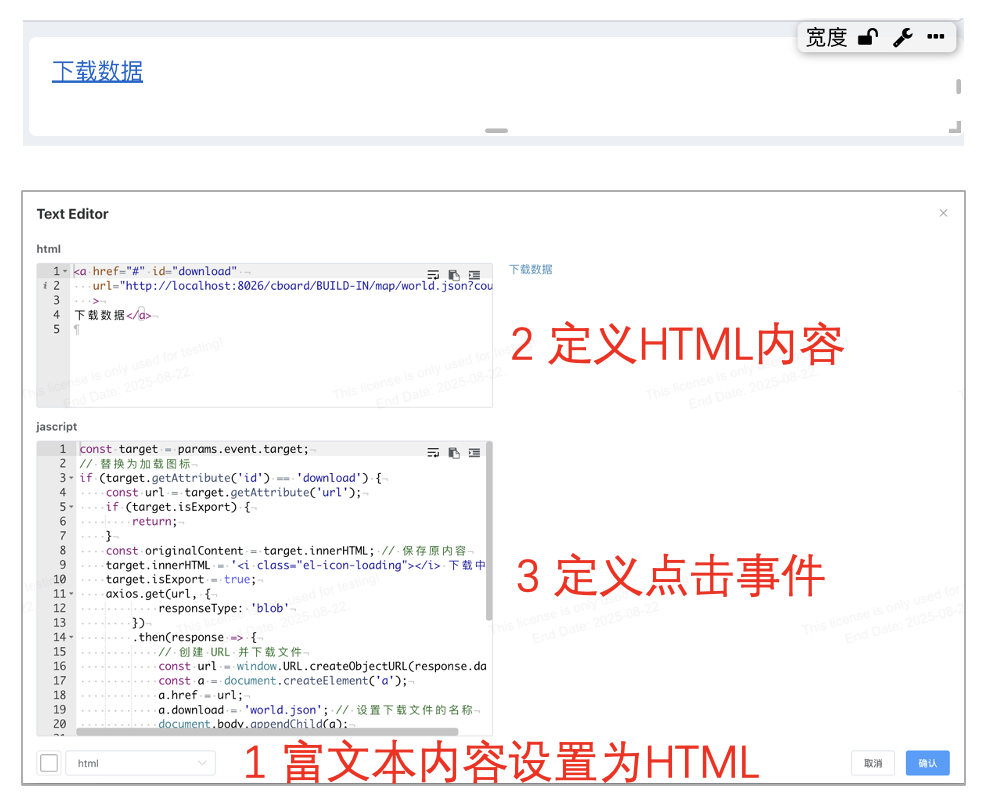
# 富文本支持点击事件JS自定义
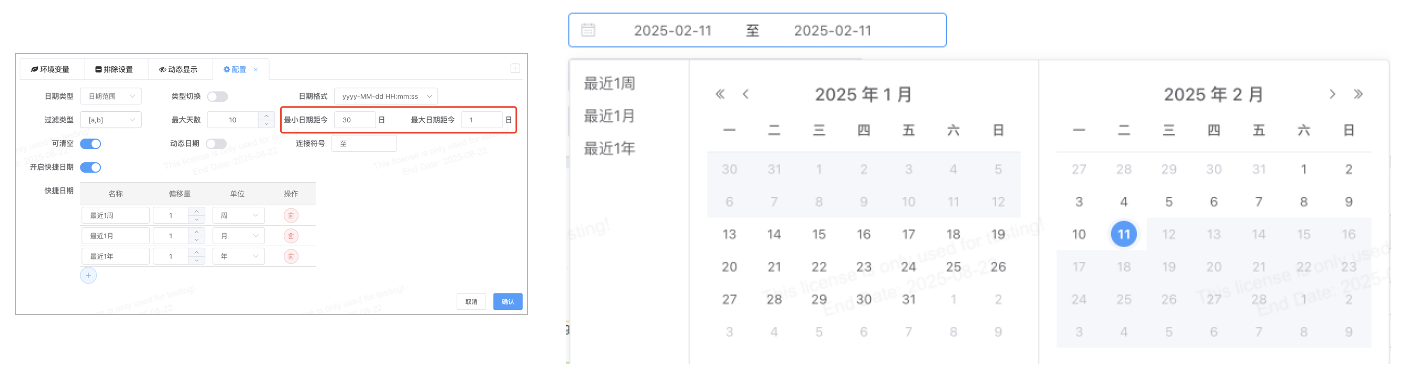
# 日期范围支持设置最小、最大可选日期
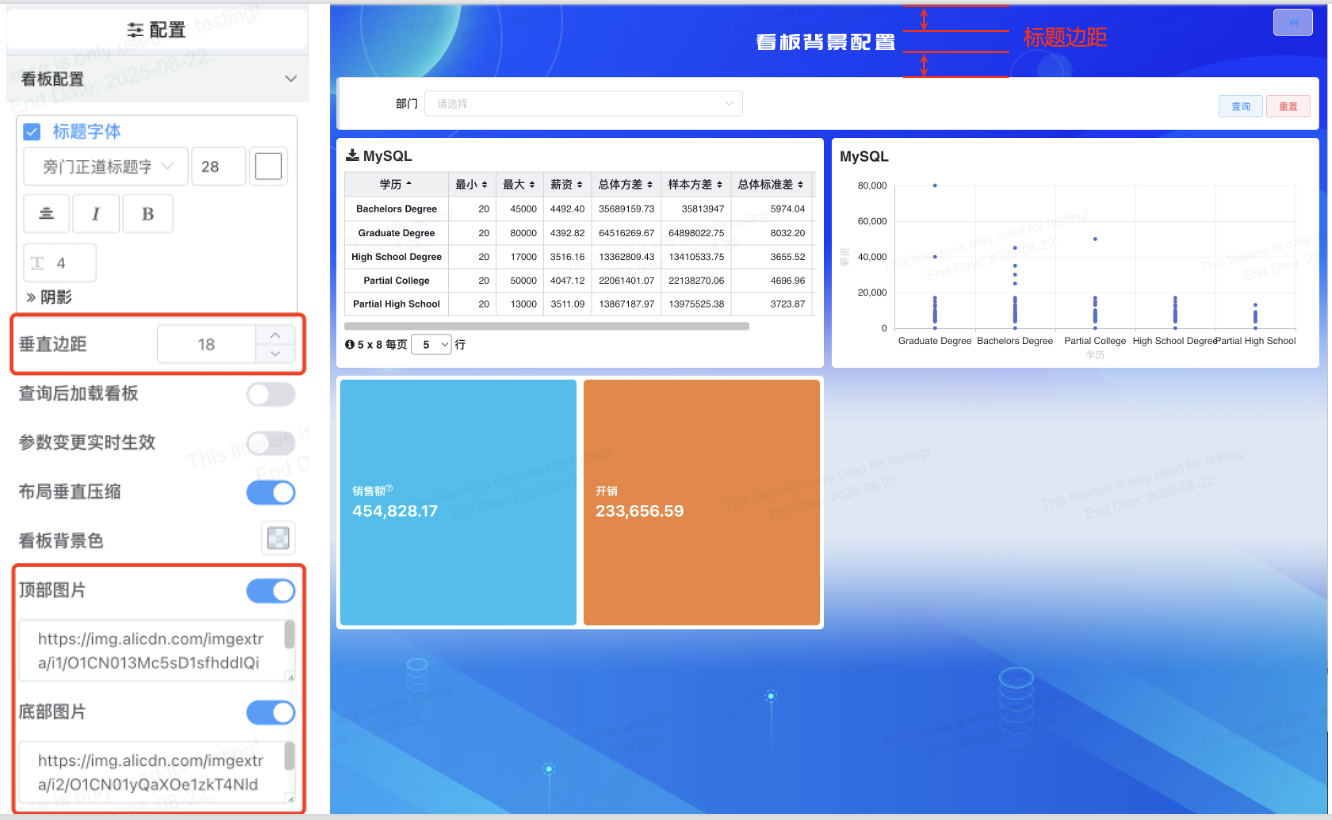
# 看板标题,背景配置
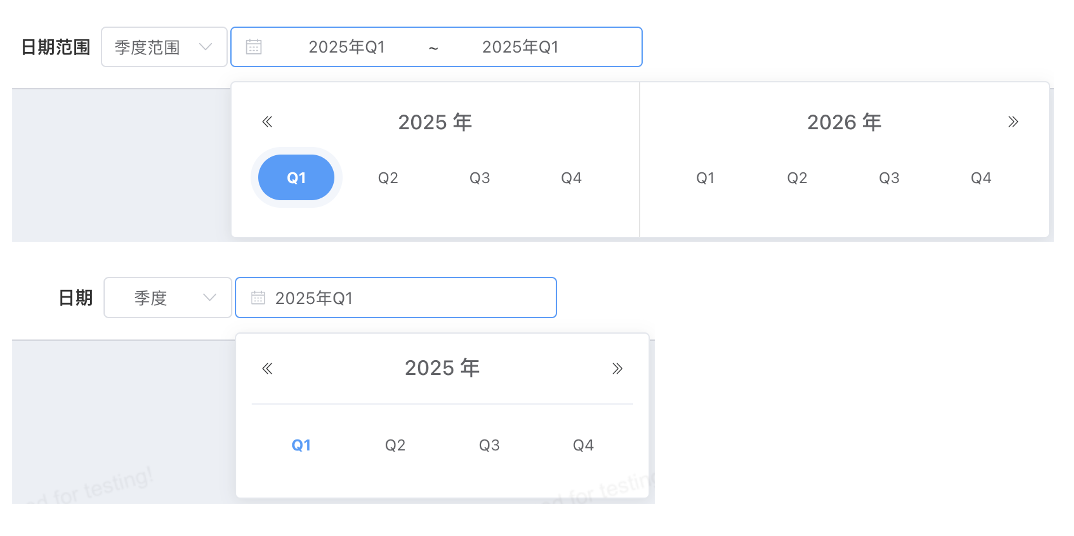
# 日期、日期范围按季度查询
# 其他
- [优化] JDBC数据源兼容字符串转日期,数值不正确的问题,如2月有30天这种错误
- [优化] 上传文件限制图片,在原来前端限制文件类型基础上增加服务端验证文件后缀操作
- Druid 连接池控制台用户名密码可配置
druid.console.enable=true
druid.console.username=root
druid.console.password=root123
1
2
3
2
3
- Windows系统下bat启动脚本增加jdk切换
- Nodejs 服务打包为pkg,避免nodejs依赖
# 修复
- [修复] Http查询formData回选为空的问题
- [修复] 表达式编辑器没有字段补全的问题
- [修复] 计算字段在维度分组中成员获取问题
- [修复] 自助分析切换数据集,保存之后会重新加载老数据集的问题
- [修复] 指标卡样式更新之后没有联动事件
- [修复] 对齐0值不工作的问题
- [修复] 经纬度地图名称位置解析时带行政区域解析失败的问题
- [修复] 交叉表百分比样式负值颜色不生效的问题
- [修复] Open JDK 大屏背景图上传失败问题
- [修复] 指标distinct过滤下推数据源语法问题