数据源
2021-6-29 About 20 min
目前支持以下数据源连接:
- JDBC数据源
- TextFile (文本文件,Excel,
1.4.2之后支持上传) - Http接口
- ElasticSearch 1.x, 2.x, 5.x (原生读取Index与Mapping,根据用户拖拽生成查询DSL)
- Kylin 1-4 (原生读取kylin Model,根据用户拖拽生成查询SQL)
- MongoDB
# 关系型数据库(JDBC数据源)
我们不纯粹为了宣传而罗列各种数据库产品,懂JDBC原理的都知道没有意义。基本上所有关系型数据库都能支持。 或许会存在一点点语法兼容问题,但是修改起来都比较简单。遇到后台日志抛语法错误异常请在github上面提issue,附上详细的异常日志和操作步骤,我们会协助解决,更加欢迎提PR合并解决方案到我们的版本。
Tips
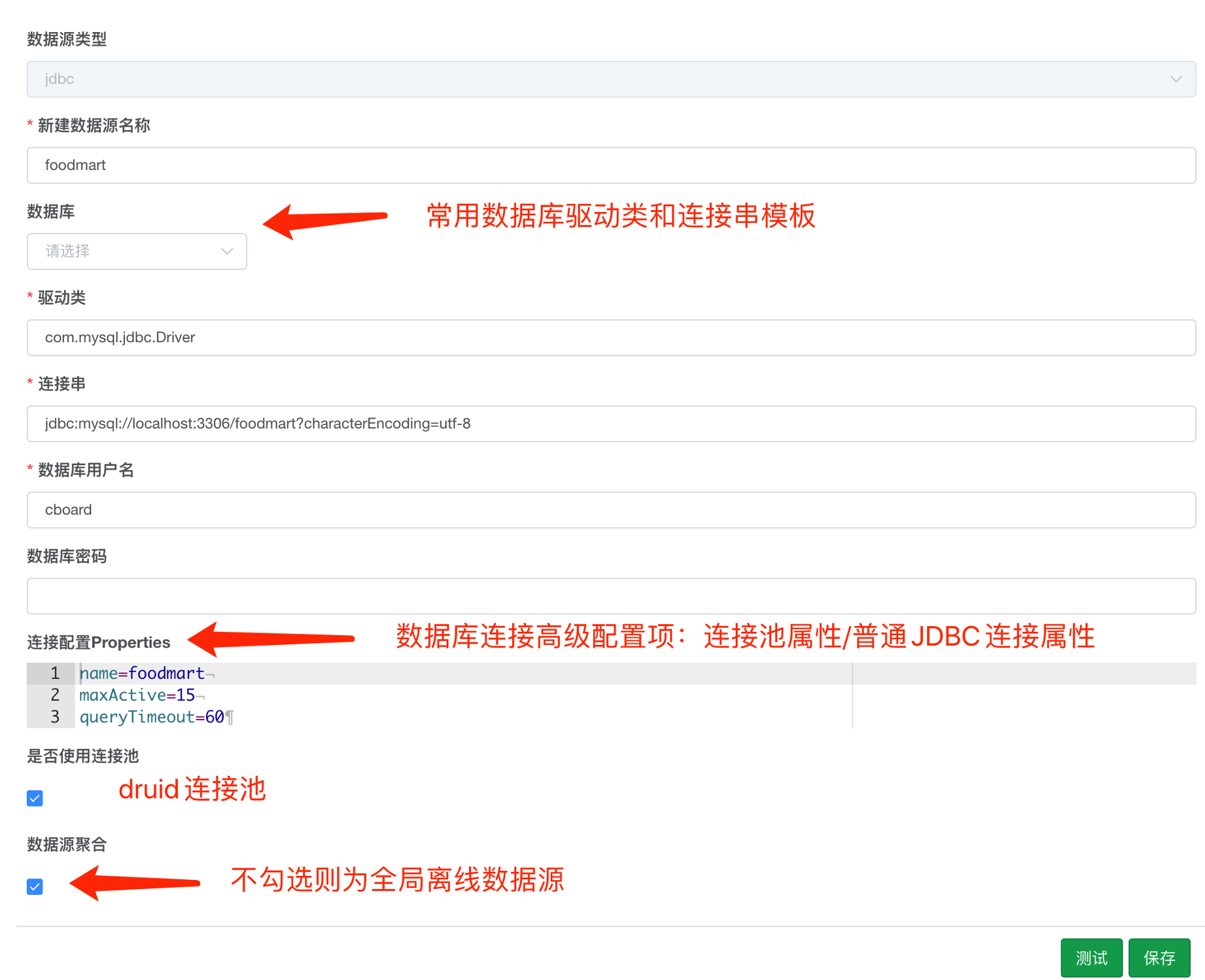
- 填写完毕之后可以点击测试按钮,输入简单的sql查询测试数据源与CBoard之间的连通性
是否使用连接池设置数据源是否通过druid连接池的方式连接数据源,数据源聚合默认配置,即引擎每次会解析用户的拖拽配置动态的生成查询语句下推数据源执行, 详细解释请参考性能优化
连接池的作用
对于一个简单的数据库应用,由于对于数据库的访问不是很频繁。这时可以简单地在需要访问数据库时,就新创建一个连接,用完后就关闭它,这样做也不会带来什么明显的性能上的开销。
但是对于一个复杂的数据库应用,情况就完全不同了。频繁的建立、关闭连接,会极大的减低系统的性能,因为对于连接的使用成了系统性能的瓶颈。
连接复用。通过建立一个数据库连接池以及一套连接使用管理策略,使得一个数据库连接可以得到高效、安全的复用,避免了数据库连接频繁建立、关闭的开销。
# 连接属性配置
# 1. 普通JDBC连接
普通JDBC连接属性配置之后,作用效果对应源代码如下:
String driver = dataSource.get(DRIVER);
String jdbcUrl = dataSource.get(JDBC_URL);
Class.forName(driver);
// 获取用户自定义properties
Properties props = new Properties(getDsrProps());
return DriverManager.getConnection(jdbcUrl, props);
1
2
3
4
5
6
7
2
3
4
5
6
7
从1.5.1开始properties配置支持变量

# 2. Druid连接池配置
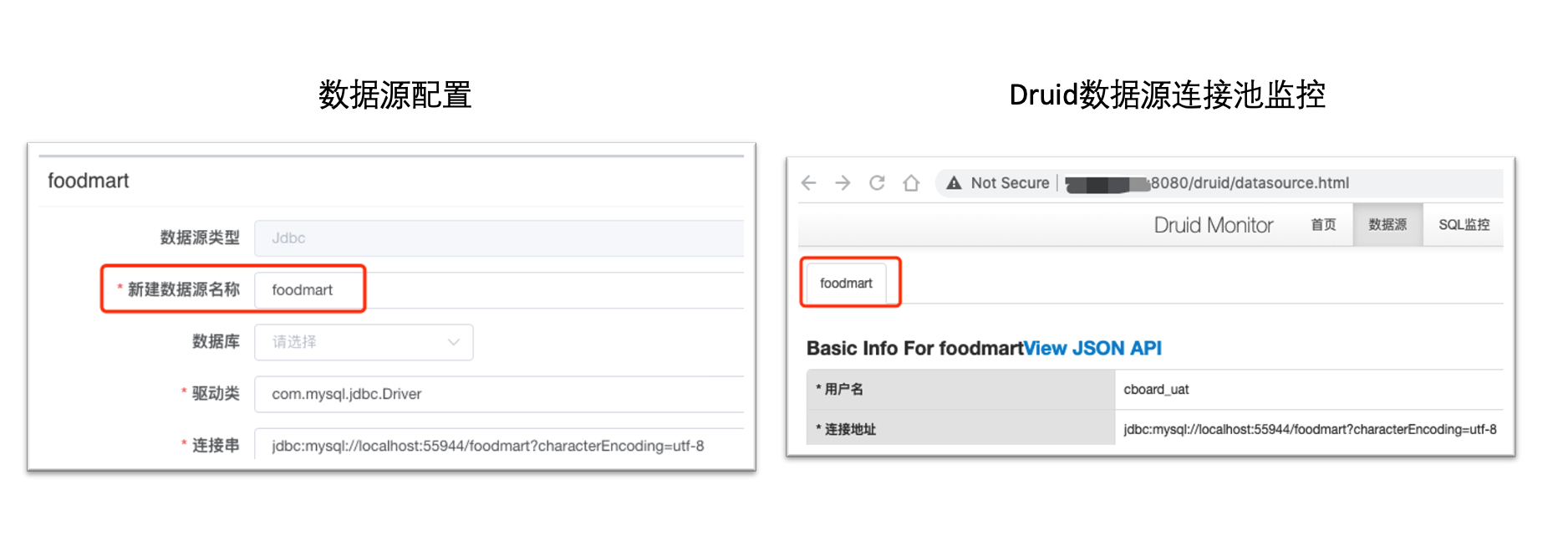
对于使用了连接池配置的jdbc数据源,可以通过访问 http://host:port/context/druid 查看连接池状态
点击参见Druid文档 (opens new window)
常用配置
| 配置 | 缺省值 | 说明 |
|---|---|---|
| name | 配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。如果没有配置,将会生成一个名字,格式是:"DataSource-" + System.identityHashCode(this). | |
| initialSize | 0 | 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时 |
| maxActive | 10 | 最大连接池数量 |
| maxIdle | 8 | 已经不再使用,配置了也没效果 |
| minIdle | 最小连接池数量 | |
| maxWait | 获取连接时最大等待时间,单位毫秒。 |
# 3. Druid连接池名称
监控连接池状态,老版本连接池的名词为随机字符串,需要数据源管理员在properties配置栏增加name属性才会显示为识别性高的连接池名称,1.4.2版本在没有配置name属性时将会默认使用数据源名称为作为连接池名称,便于维护管理
关于Hive
理论上Hive也可以通过JDBC的方式连接,考虑到查询延迟太高不适合做及时交互查询引擎,不推荐引入。
# 驱动引入方式
添加JDBC数据源之前确认应用中已经包含了对应的JDBC驱动包,其他驱动可自行添加将驱动拷贝到ext-lib或联系我们预置, 当前版本项目中预置的驱动有:
| 数据库 | 版本 | 说明 |
|---|---|---|
| MySQL | mysql / mysql-connector-java / 8.0.22 | |
| SQLServer | com.microsoft.sqlserver / mssql-jdbc / 8.2.2.jre8 | |
| Oracle | com.github.noraui / ojdbc8 / 12.2.0.1 | |
| Postgresql | postgresql / 42.6.0 | |
| Clickhouse | ru.yandex.clickhouse / clickhouse-jdbc / 0.2 | |
| Presto | com.facebook.presto / presto-jdbc / 0.231.1 | |
| Phoenix | phoenix-queryserver-client-5.0.0-HBase-2.0 |
# TextFile 文本数据源
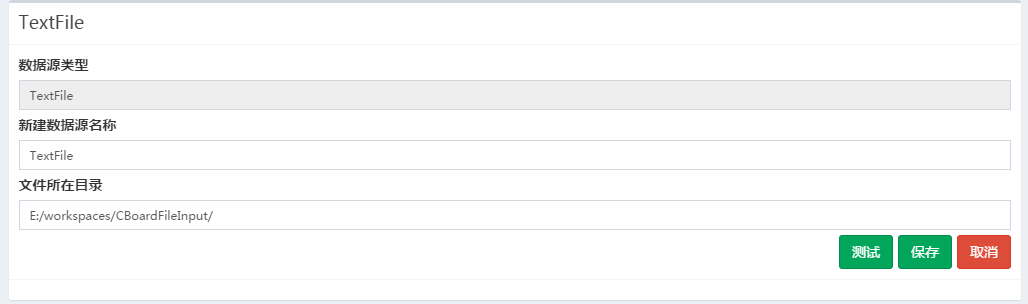
文本数据只能读取CBoard应用服务器本地文件,1.4.2之前的版本使用者需要自己架设ftp服务器单独维护文本文件的上传与管理。
| 配置项 | 说明 |
|---|---|
| 文件所在目录 | 该目录指BI服务器上的目录,需提前创建好, 后续数据集中使用该数据源,上传文件时会传到此处配置的目录 |
目录权限
建议配置的基础目录有新建文件与删除文件操作权限, 如果没有新建与操作权限,仅有只读权限,也是能够使用的,只是文件上传会失败
# HTTP数据源v1.7.0
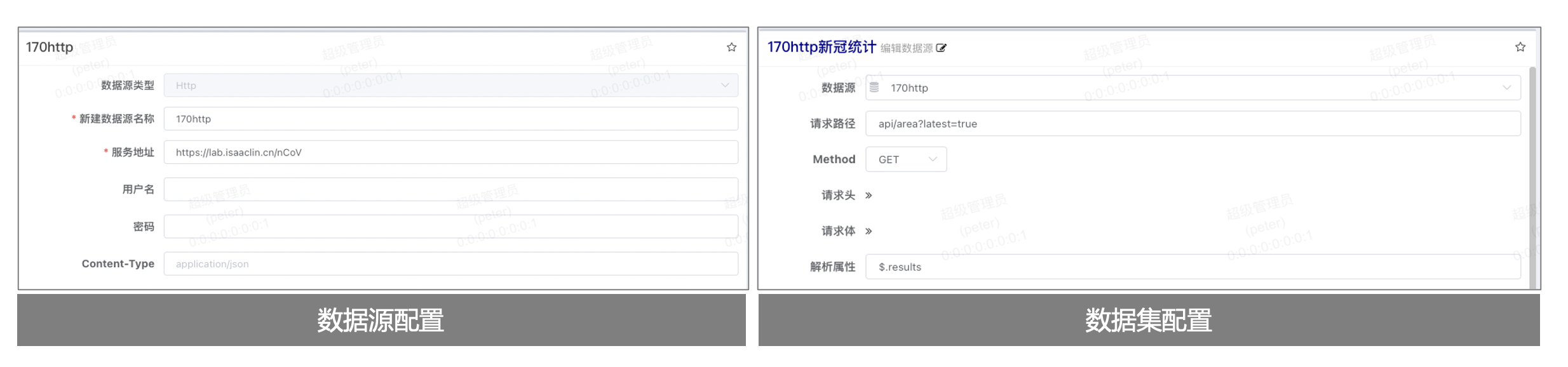
# 数据源配置
- 服务地址为地址前缀, 不需要以斜杠结尾, 会与查询请求地址组合为完整请求地址
- 用户名/密码目前仅支持用于Basic Authentication
- 可以不设置, 具体类型会请求体自动适配
# Kylin
# JDBC方式连接
添加了kylin的jdbc依赖,可以直接连接,连接方式如下
Driver :org.apache.kylin.jdbc.Driver
JdbcUrl:jdbc:kylin://<host>:<port>/<project>
1
2
2
用JDBC方式连接Kylin可以选数据源聚合也就是聚合下推Kylin,或者使用CBoard提供的内置聚合器,通过查询预聚合返回小的结果集,结果集缓存在CBoard服务器上做二次聚合。 聚合下推原理参照性能优化章节。
注意
非数据源聚合的连接,切记注意数据集或者Query查询结果集大小。
关于Kylin1.6对子查询支持结果异常问题:
CBoard中采用的基于数据集定义的子查询嵌套之后group by的形式聚合下推数据源。 我们在实际使用中遇到过查询结果不准的bug,遇此情况可以通过图表设计模块下预览查询功能查看调试实际执行的Query。
或者改用下面Kylin原生数据源
# Kylin原生连接
Kylin原生连接通过restful接口读取解析Kylin数据模型
原生连接模式下聚合操作只会在数据源进行。
# Elasticsearch
IBI Elasticsearch数据源适配采用restful url + DSL查询的方式适配,不需要转sql查询,目前测试最高兼容版本8.x, 更高版本只要没有重大变更基本都可以兼容,如有不兼容场景请联系我们更新适配。
# ES 数据源配置
| 配置项 | 说明 |
|---|---|
| 服务器url | 必填, 如: http://host:port |
| 用户名 | 选填, ES服务开启了standard HTTP basic authentication 之后需要填写 |
| 密码 | 选填 |
# 变量支持v1.8
在配置输入项中使用变量, 支持读取在系统配置中配置的属性和application.properties中user.前缀的配置项, 通过连接配置可以从数据源头切换不同环境的数据展示

# 密码加密v1.10.0
从1.10开始支持数据源中配置的密码自动加密,加密之后的配置将不能与旧版本兼容,旧版本的配置在新版本中点击保存将进行加密操作