Elastcsearch数据集
2023-5-5 About 8 min
Tips
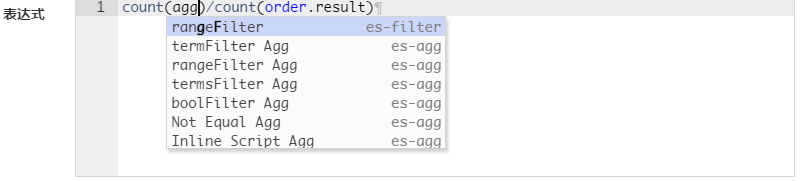
为了减少对ES版本以及第三方ES库的依赖,CBoard采取restful + DSL连接与查询模式。所以ES的使用需要使用者(尤其是建模者)对ES基本概念有所了解,之外还需要掌握一些DSL语法。
ES查询需要参数需要精确到Type,Index名称可使用通配符原理与ES DSL查询URL参数一样。
由于ES里面存储的数据大多为明细数据,时间维度聚合的时候粒度需要调整为时间段date_histgram,而默认的聚合级别为term也就是关键词,所以在使用时间维度聚合之前需要调整聚合粒度。
# 聚合覆盖
CBoard 提供了三类常见的聚合 Bulket 覆盖辅助输入,具体可配置参数请参考官方文档Bucket Aggregations (opens new window)
- date_hist: 日期类型直方图聚合
- number_range: 数字区间聚合
- number_hist:数字直方图

语法如下(可以重复覆盖多个列的聚合):
{
"columnname":{
"<aggregation_type>" : {
<aggregation_body>
}
}
}
---------------------------------
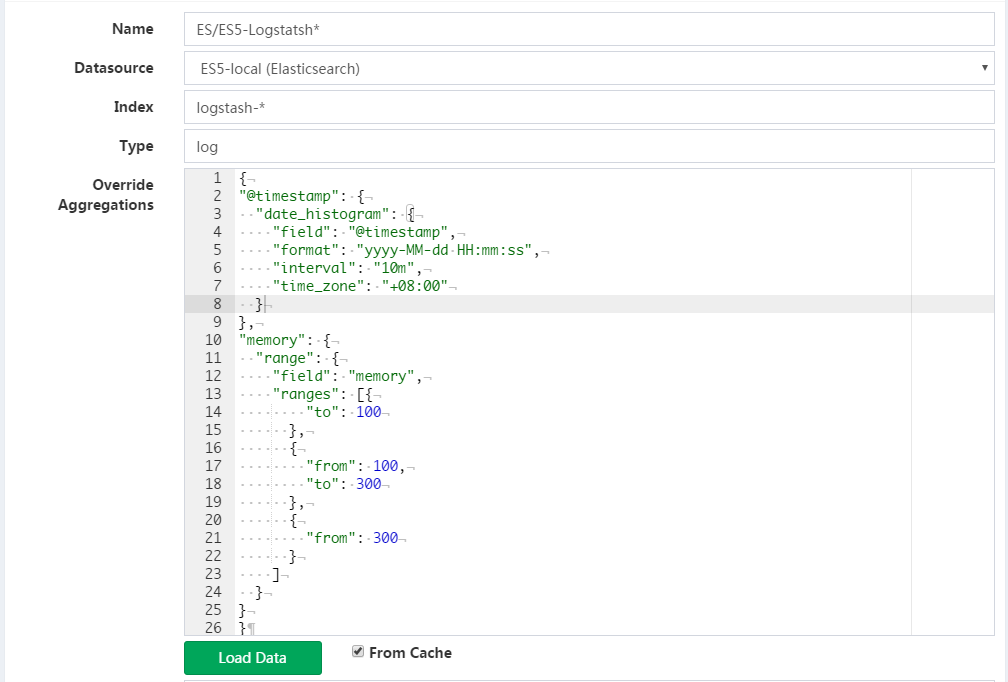
样例:
对时间戳字段timestamp(long类型)按每10分钟一段进行聚合, 数字memory按自定义区间聚合
{
"timestamp": {
"date_histogram": {
"field": "timestamp",
"format": "yyyy-MM-dd HH:mm:ss",
"interval": "10m",
"time_zone": "+08:00"
}
},
"memory": {
"range": {
"field": "memory",
"ranges": [
{
"to": 10000
},
{
"from": 10000,
"to": 30000
},
{
"from": 30000
}
]
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 日期字段+区间
用于生成按索引的日期后缀与查询过滤, 该功能属于维护,可能不太稳定
当设置有日期字段之后,默认索引以 indexName-yyyy.MM.dd名称,
- 字段获取时使用通配符路径 http://localhost:9200/index_name-*/_mapping
- 查询搜索是日期字段没有设置过滤条件,使用默认的日期组件 http://localhost:9200/index_name-2023.01.01,index_name-2023.01.02,index_name-2023.01.03/_mapping
- 当日期字段带有过滤条件时,日期后缀会结合过滤条件自动生成
# TimeZone
索引日期时区配置,支持配置+02:00与时区名称Asia/Shanghai
# 全局过滤条件
可以设置单个或者多个全局过滤条件,过滤条件中可以使用内置日期变量,从而实现动态全局过滤的效果
{
"range": {
"time": {
"gt": "${cdt.addMonth(-1, 'yyyy-MM-dd')}"
}
}
}
1
2
3
4
5
6
7
2
3
4
5
6
7
[
{
"range": {
"time": {
"gt": "xx"
}
}
},
{
"term": {
"status": "published"
}
}
]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
# 脚本衍生维度配置
在前面中的聚合覆盖设置在数据集查询之上,相当于全局查询列聚合覆盖;同时如果想对一个列采取多种分桶策略,可以在 Schema 树上多次引用可选列,然后编辑 custom 信息
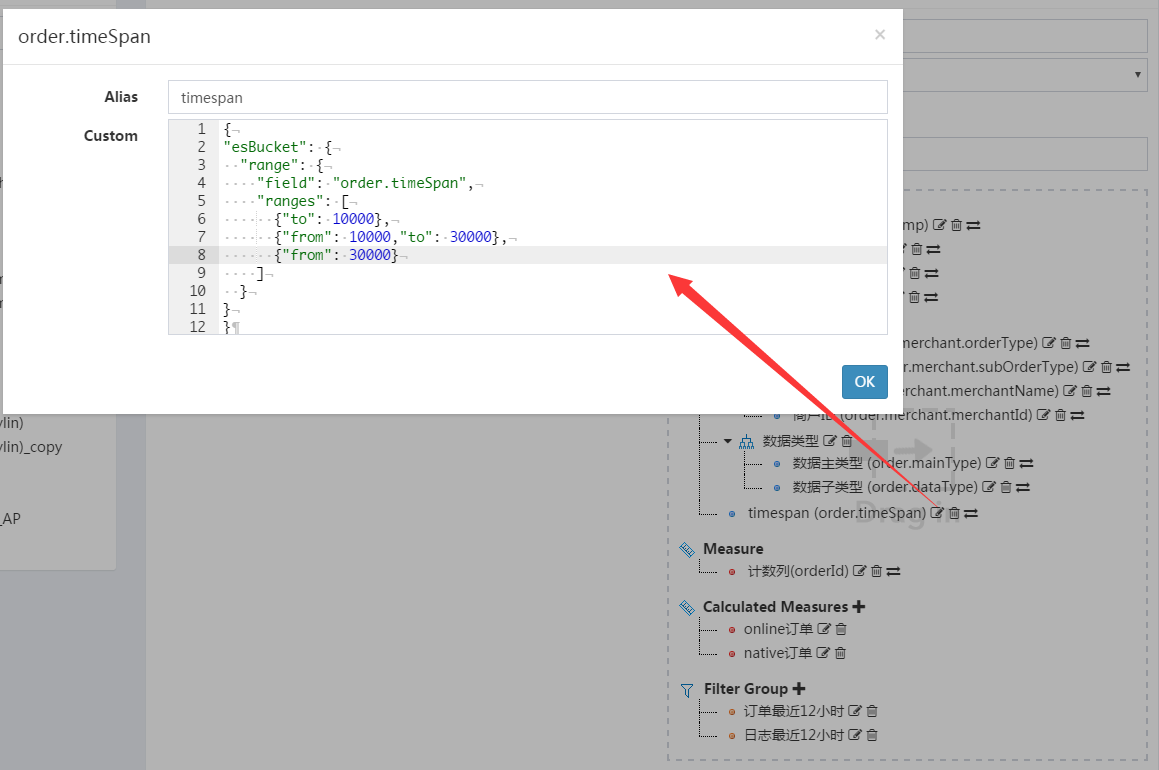
{
"esBucket": {
"<aggregation_type>" : {
<aggregation_body>
}
}
}
1
2
3
4
5
6
7
2
3
4
5
6
7
注意
esBucket为内置关键词,不能替换
# 高级聚合表达式
除了常规聚合统计之外,ES 的聚合表达式还支持Filter Aggregation (opens new window), 用作条件统计,或者静态占比
语法如下:
count/sum/avg/max/min("{
'coulumn': '用于聚合的column',
'filter': <filter_body>
}")
-------------------------------
count("{
'column': 'orderId',
'filter': {
'term': {
'order.platform': 'online'
}
}
}")
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
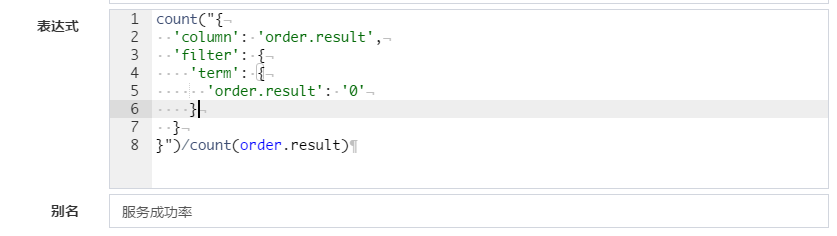
CBoard 也内建了一些常用过滤器输入辅助