LOD表达式
2024-10-21 About 28 min
LOD函数的全称是详细级别表达式(Level Of Detail Expressions)。它主要是为了克服一些表达式之间计算粒度不一致的问题,本文将详细为您介绍如何使用LOD函数。
# 使用场景
详细级别表达式,其中详细级别指数据聚合粒度的层次,不同的级别代表着数据不同的聚合度和粒度,能够处理在一个可视化视图中包含多个数据详细级别的问题。
如果分析过程中需要添加一个维度,其明细程度高于或者低于已有视图的可视化明细程度,但又不希望改变现有图形展示内容,就可采用详细级别表达式功能。
# 语法说明
{[FIXED | INCLUDE | EXCLUDE] <维度声明> : <聚合表达式>}
1
# FIXED
{FIXED <维度声明> : <聚合表达式>}
- FIXED 详细级别表达式使用指定的维度计算值,而不引用视图详细级别,也就是说,不考虑视图中的任何其他维度。
- FIXED 详细级别表达式会忽略除自助分析设计器上的筛选过滤。
从FIXED的特性可看出,由于其计算时值考虑自身维度声明,不考虑视图上任何其他维度,所以其运行在计算字段生成阶段
详细介绍请参考 计算字段#LOD FIXED
# 汇总级LOD表达式
EXCLUDE、INCLUDE的作用是排除或增加视图中的维度,再做汇总,由于增加维度之后,汇总的颗粒度与视图不再相同,因此这两种LOD表达式都运行在汇总表达式级别
# 图形化配置
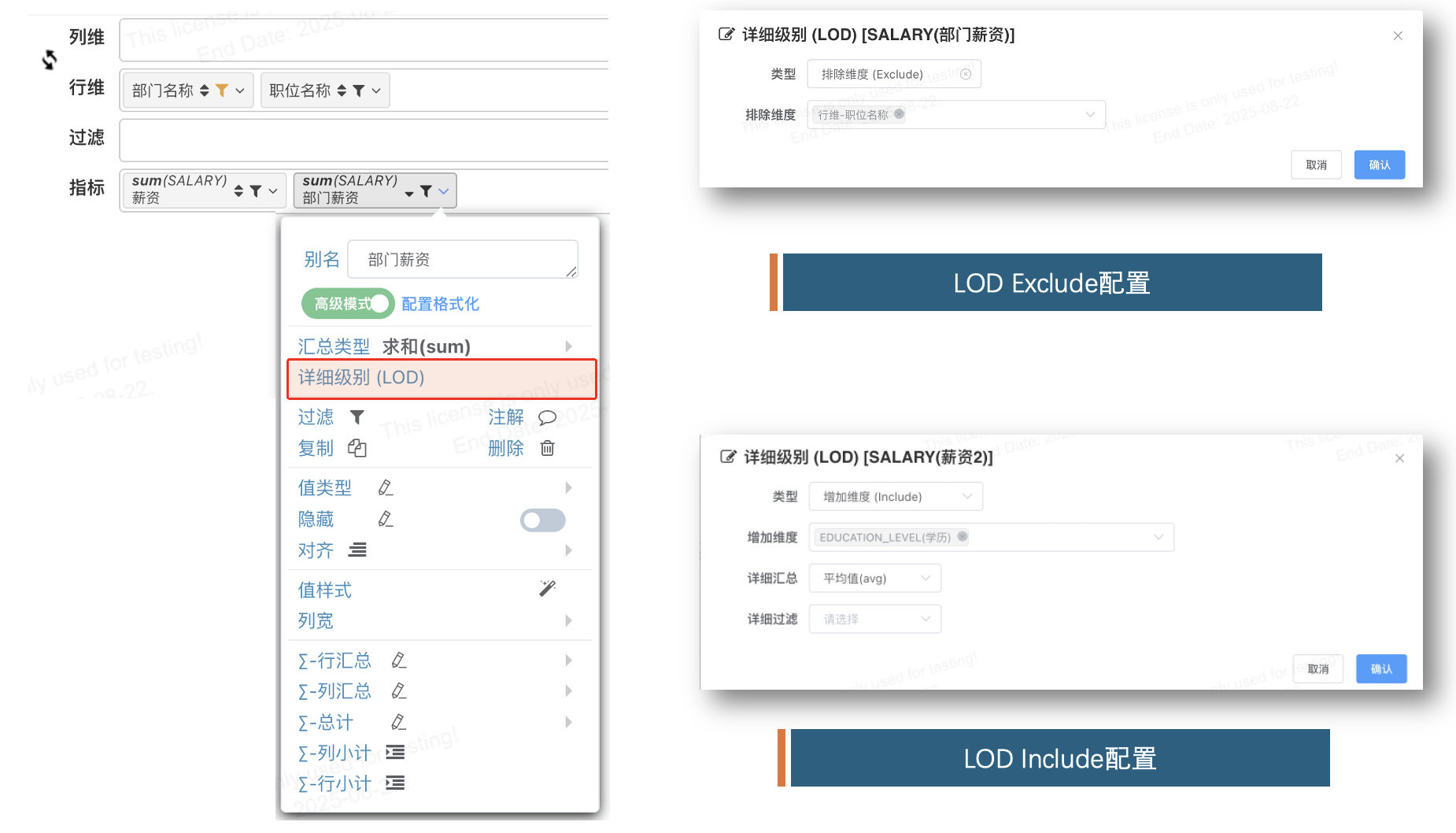
# 表达式配置
# INCLUDE
{ INCLUDE <维度声明> : <聚合表达式> [: <过滤条件>] }
1
在现有的汇总粒度上增加维度, INCLUDE 数据颗粒度变细,要与现有视图合并则需要在INCLUDE维度之后再在视图颗粒度上做一次附加汇总
{ INCLUDE `dim`[, `dim2`] : sum(`col`) [: <过滤条件>] }
1
avg({INCLUDE `dim` : sum(`col`)})
avg({INCLUDE `dim` : sum(`col`)} : `type` = 1 AND `dt` > '2024-10-01' )
sum({INCLUDE `dim` : sum(`a`)/sum(`b`)})
-- 其中dim可以是表达式如 avg({INCLUDE YEAR(`dt`) : sum(`sales`)})
1
2
3
4
2
3
4
注意
目前include表达式外层必须直接跟汇总函数,不能对INCLUDE整体做其他计算判断或者嵌套函数如:
-- 错误1-Include表达式使用函数嵌套
sum(IF({INCLUDE `dim` : sum(`col`)} > 1000, `sales`, 0))
-- 正确写法:
sum({INCLUDE `dim` : IF(sum(`col`) > 1000, `sales`, 0)})
-- 错误2-多个INCLUDE计算:
sum({INCLUDE `dim` : sum(`col1`)} + {INCLUDE `dim` : sum(`col2`)})
-- 正确写法
sum({INCLUDE `dim` : sum(`col1`)}) + sum({INCLUDE `dim` : sum(`col2`)})
sum({INCLUDE `dim` : sum(`col1`) + sum(`col2`)})
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
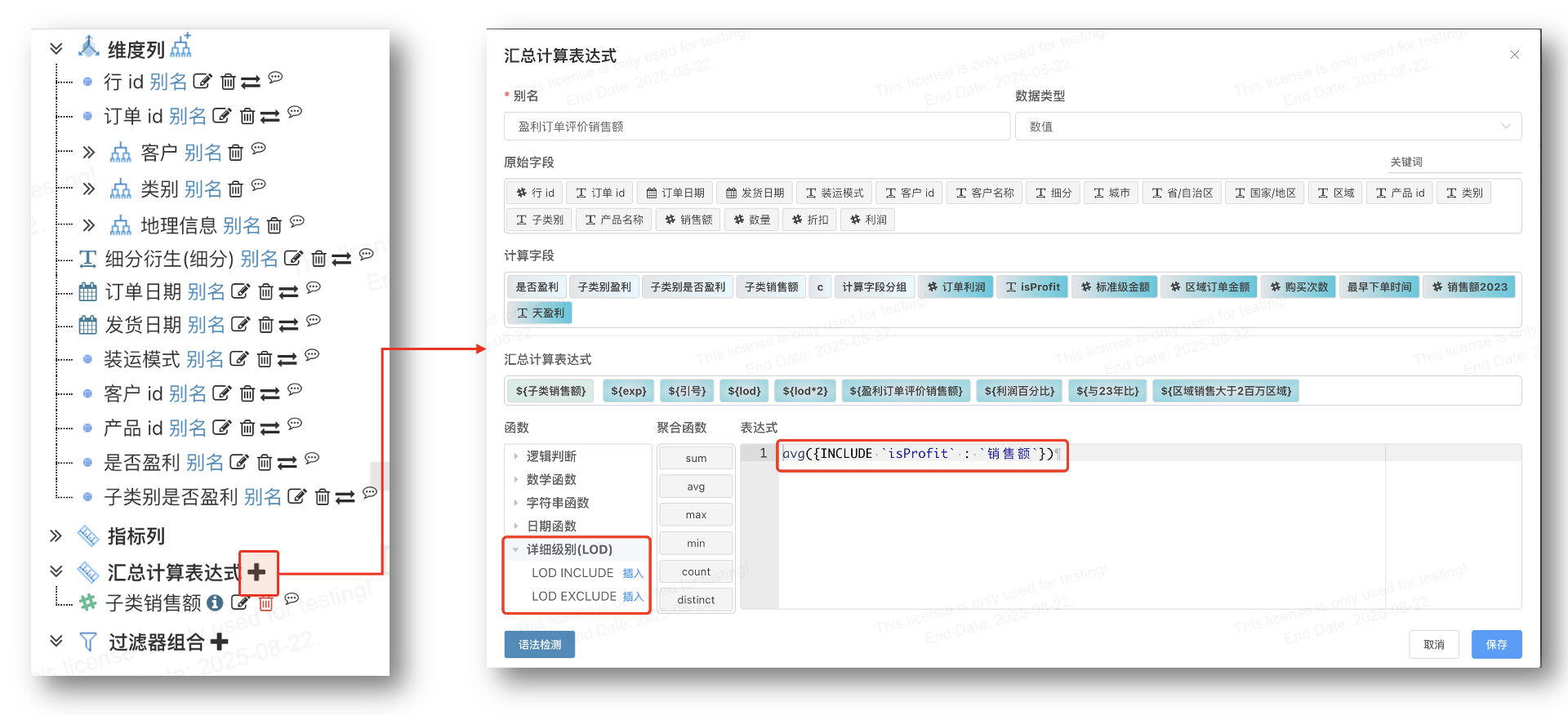
下面我们用一个最简单的实例解释INCLUDE
现在有订单表,每个订单有产品类别、子类别、金额等属性,现在需计算每个大类中子类评价销售额, 最终视图中的颗粒度只有类别一列,LOD INCLUDE表达式如:
avg({INCLUDE `子类别` : sum(`销售额`)})
1
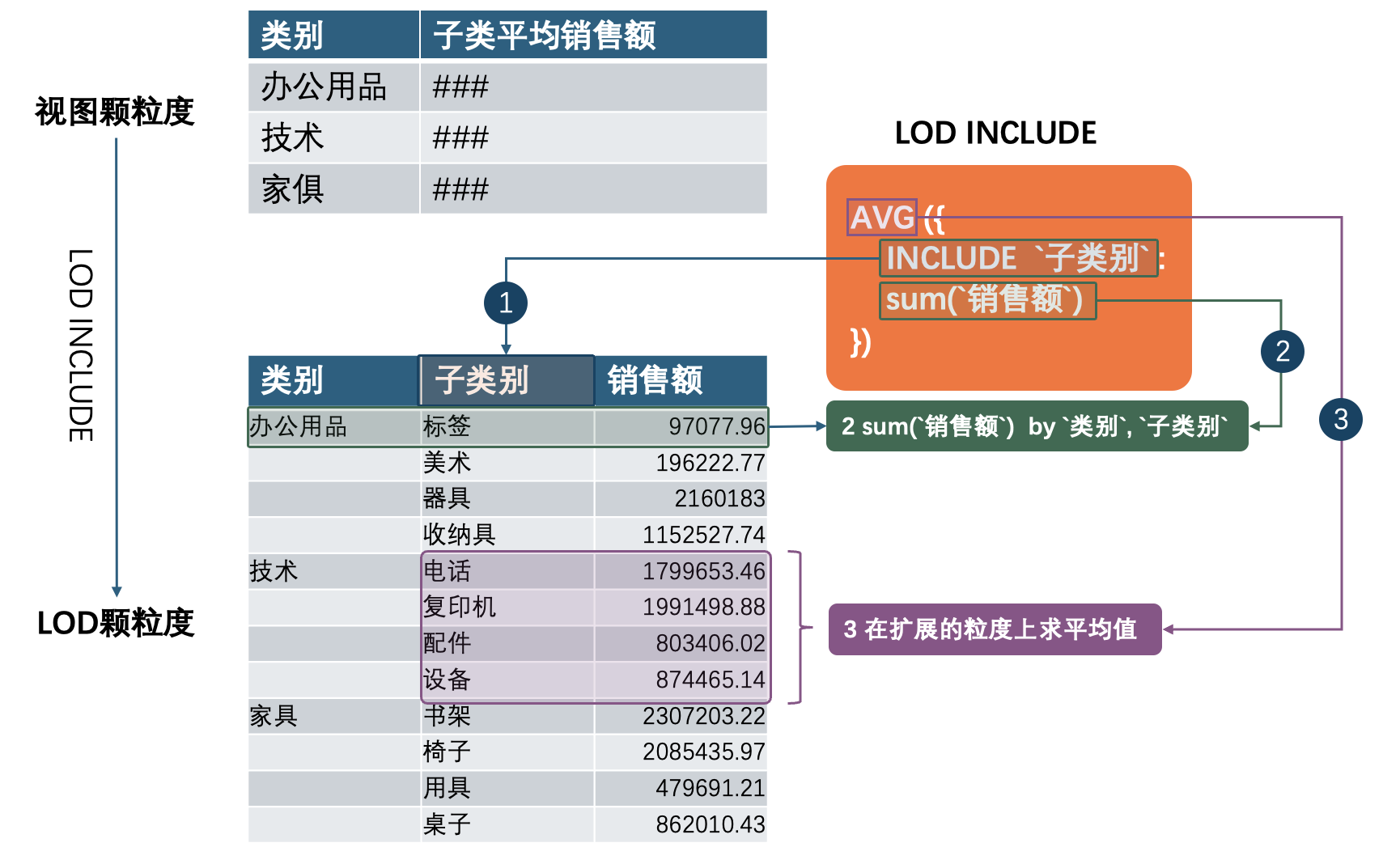
LOD工作过程如图所示:
- 新增子类别 : 在新增子类之后,颗粒度变细, 即一个大类下面有多个子类
- LOD 级别汇总*: 在LOD级别
类别,子类别上做sum(销售额)汇总计算,得到每个子类别的销售额 - 扩展粒度上求平均: 在扩展粒度上求平均值,让粒度与视图一直
# EXCLUDE
{ EXCLUDE <维度声明> : <聚合表达式> [: <过滤条件>] }
{ EXCLUDE
dim[,dim2] : sum(col) [: <过滤条件>] }
EXCLUDE与INCLUDE颗粒度变化相反,在现有的汇总粒度上排除维度,由于排除维度之后,颗粒度变粗,原来多行数据变成一行,不需要外部汇总也能与原视图匹配
{ EXCLUDE `dim` : sum(`col`) }
{ EXCLUDE `dim` : sum(`col`) : `type` = 1 AND `dt` > '2024-10-01' }
{ EXCLUDE `dim` : sum(`a`)/sum(`b`) }
1
2
3
2
3
Exclude 判断规则
- LOD表达式中:默认按维度的字段名进行对比判断是否移除
- 如果视图中的字段配置了衍生维度,如
month字段衍生为季度Quarter之后,EXCLUDEmonth将不能排除month维度,取而代之可以使用衍生维度之后的别名排除 - EXCLUDE
YEAR(dt)不能排除任何维度 - 如果使用图形化配置,下拉精确选定维度的方式,排除则不用考虑维度是否衍生
# 典型使用场景
# INCLUDE典型案例
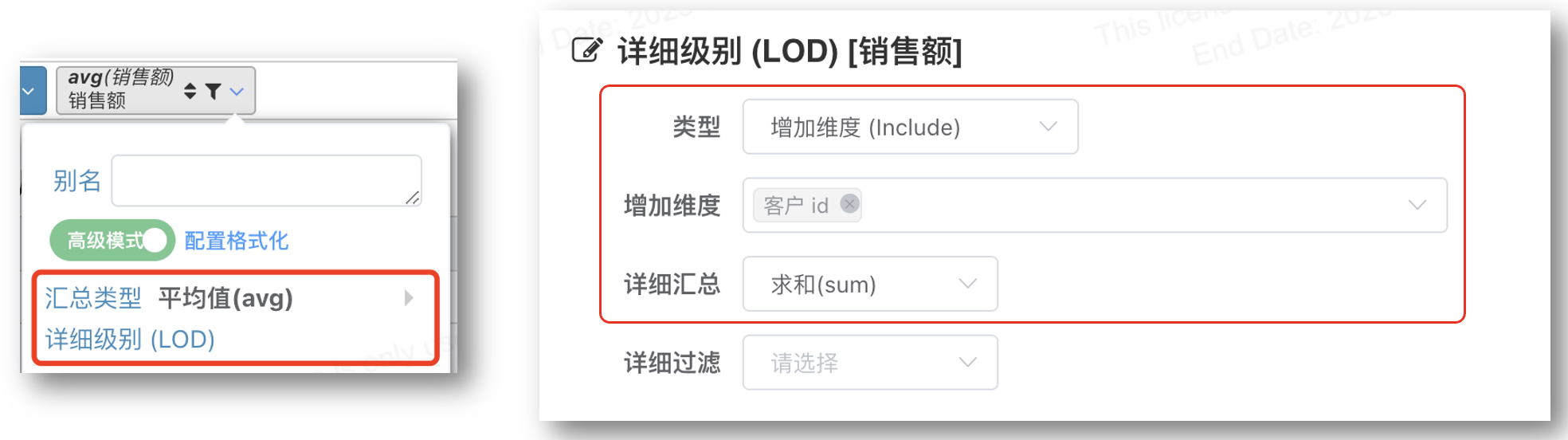
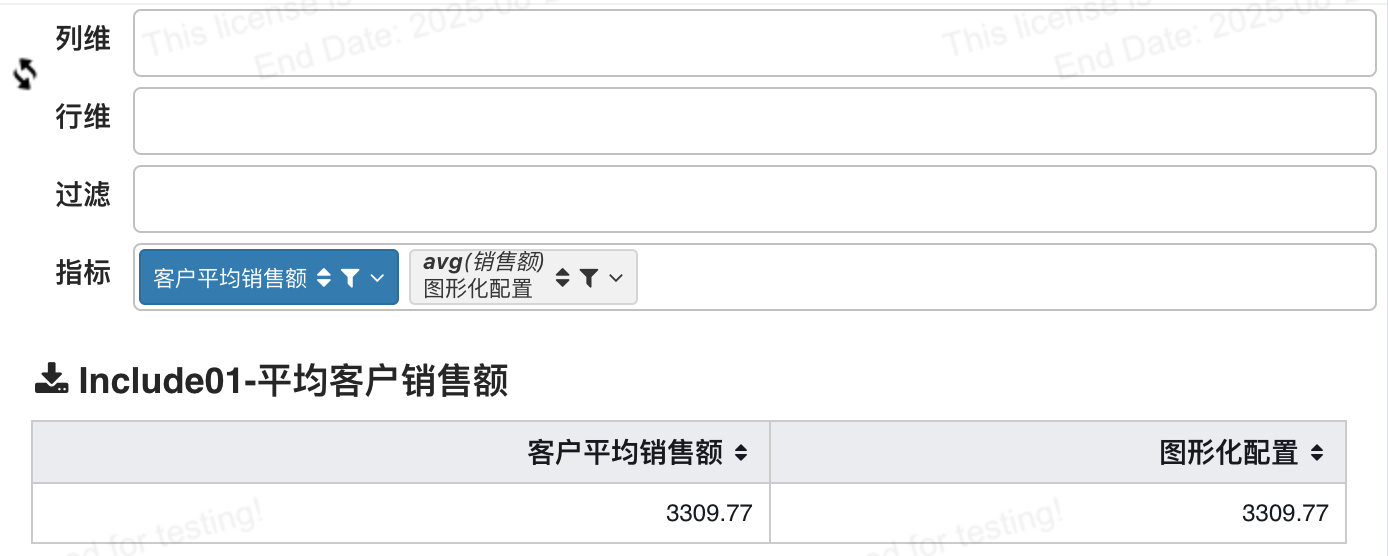
# 计算平均客户销售额
当订单表中每个客户有多个订单,甚至一个订单有多条货品,我们要计算平均客户销售额
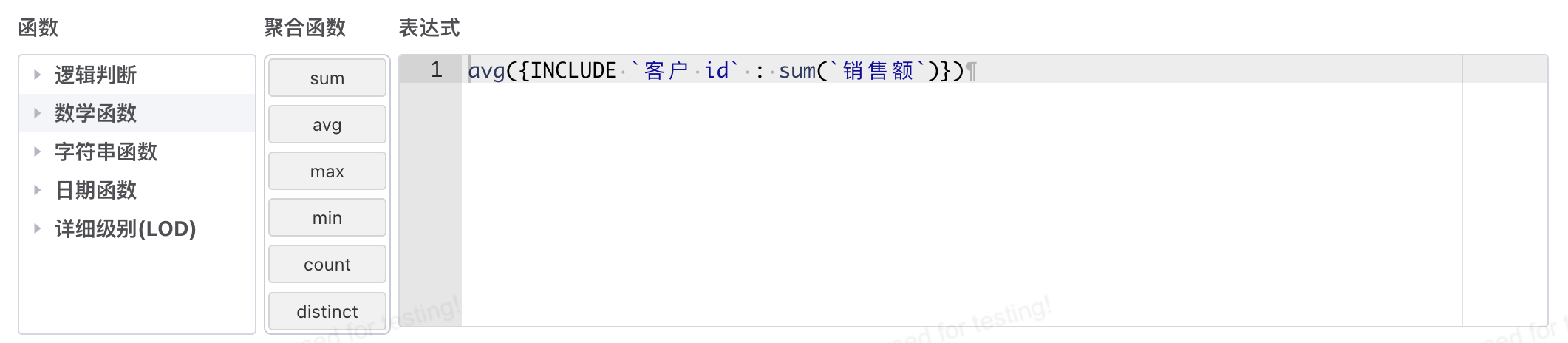
avg({INCLUDE `客户 id` : sum(`销售额`)})
1
含义:按照客户id计算每个客户的总订单金额之后求平均, 详细级别中使用的sum汇总,外层使用的avg汇总
习惯图形化配置的用户,也可以通过拖拽字段销售额,下拉配置详细级别(LOD),实现相同效果
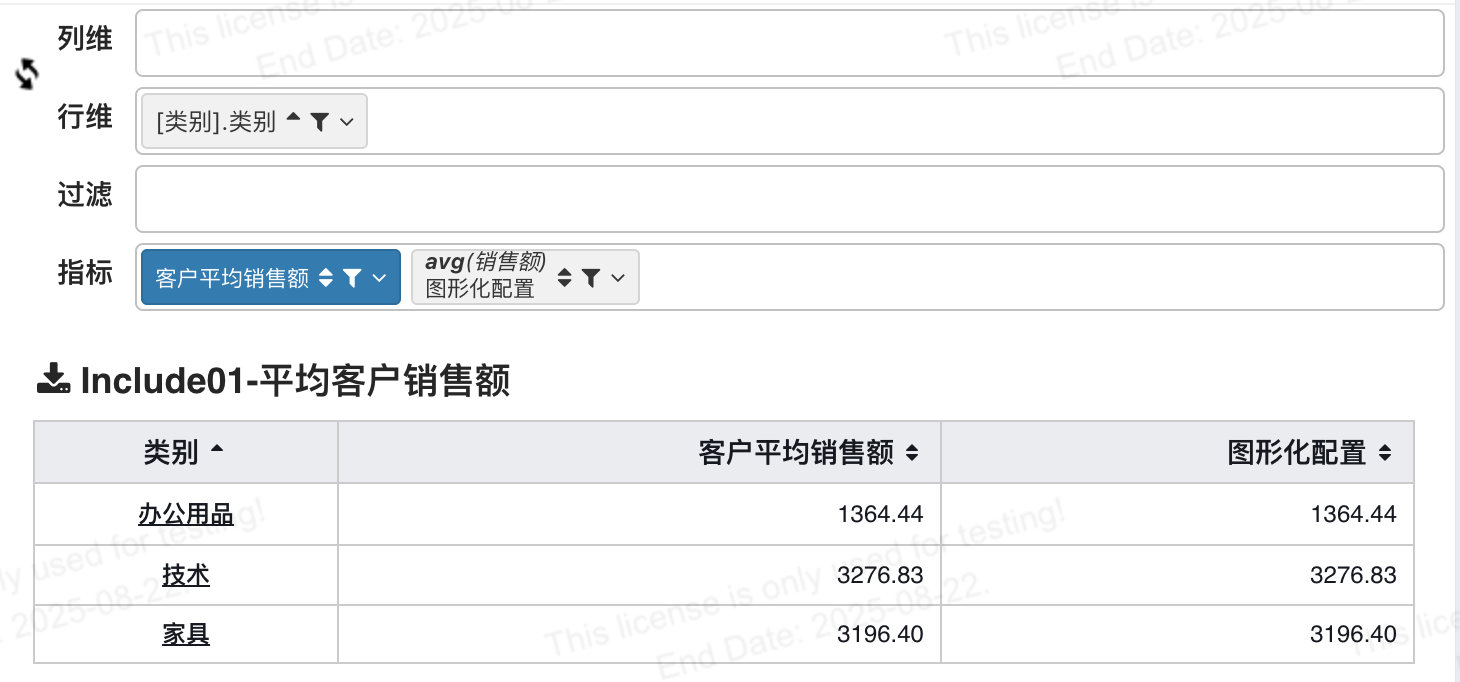
同时我们还可以进一步细分到不同类别产品之后,上面的平均值公式依旧有效
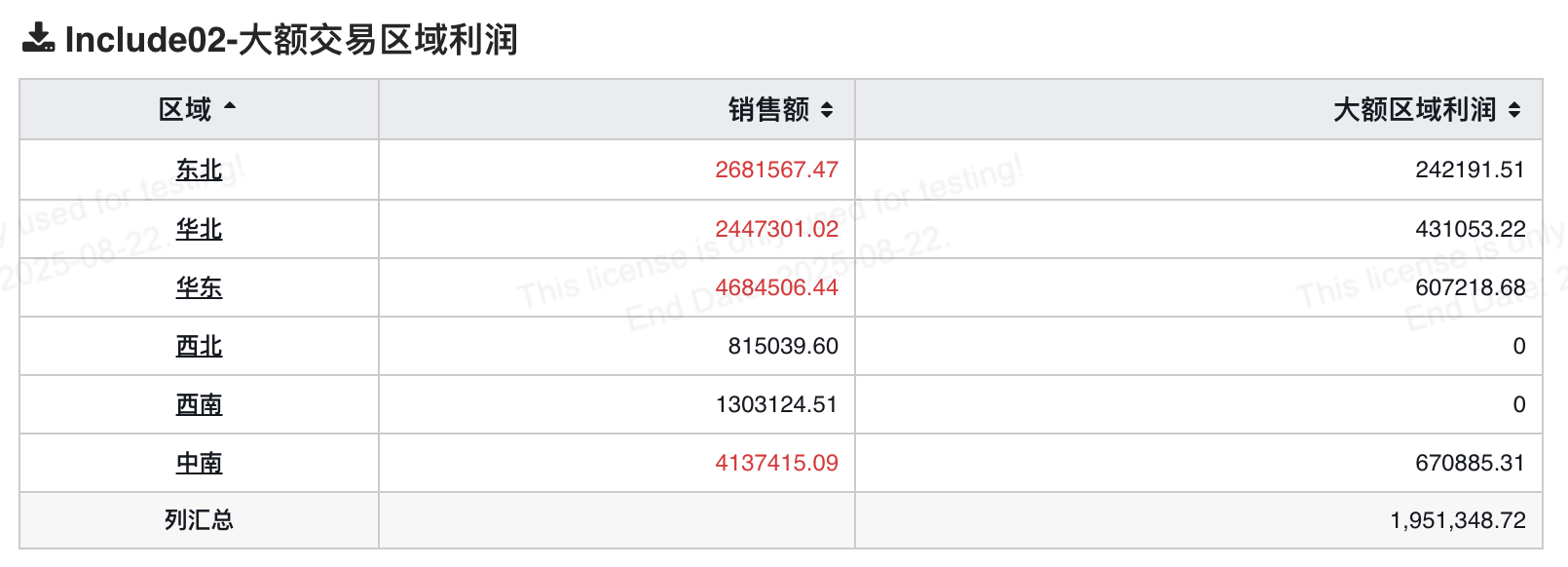
# 计算区域订单金额大于200万的区域对应的利润总额
按区域统计订单金额,计算大于50万的区域的利润总额。
sum({
INCLUDE `区域` : IF(
sum(`销售额`) > 2000000, sum(`利润`), 0
)
})
1
2
3
4
5
2
3
4
5

按区域展开验证数据,如下表所示,红色字体区域的销售额大于2000000, 对应的利润有数值,小于2000000的区域没有计算利润,列汇总值与上面的数值一致
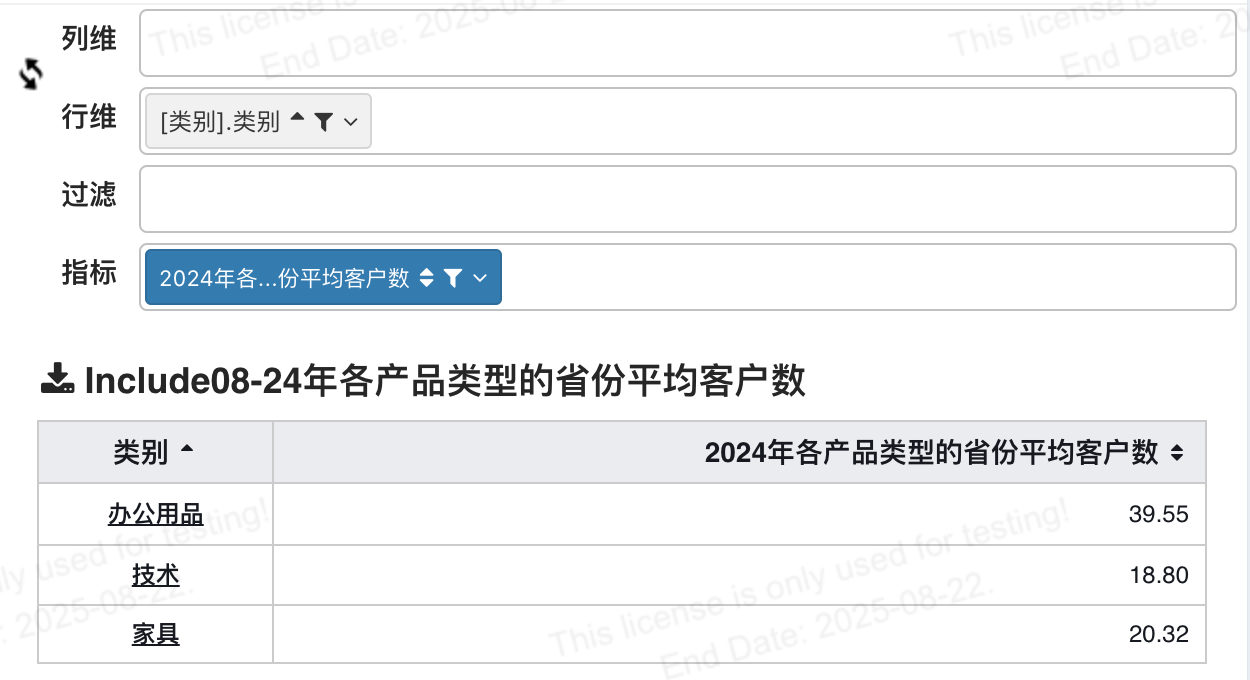
# 计算2024年各产品类型的省份平均客户数
avg({
INCLUDE `类别`, `省/自治区` :
count(distinct IF(YEAR(`订单日期`)=2024, `客户 id`, null))
})
1
2
3
4
2
3
4
# Exclude典型案例
EXCLUDE详细级别表达式将去除表达式中指定的维度后进行计算。
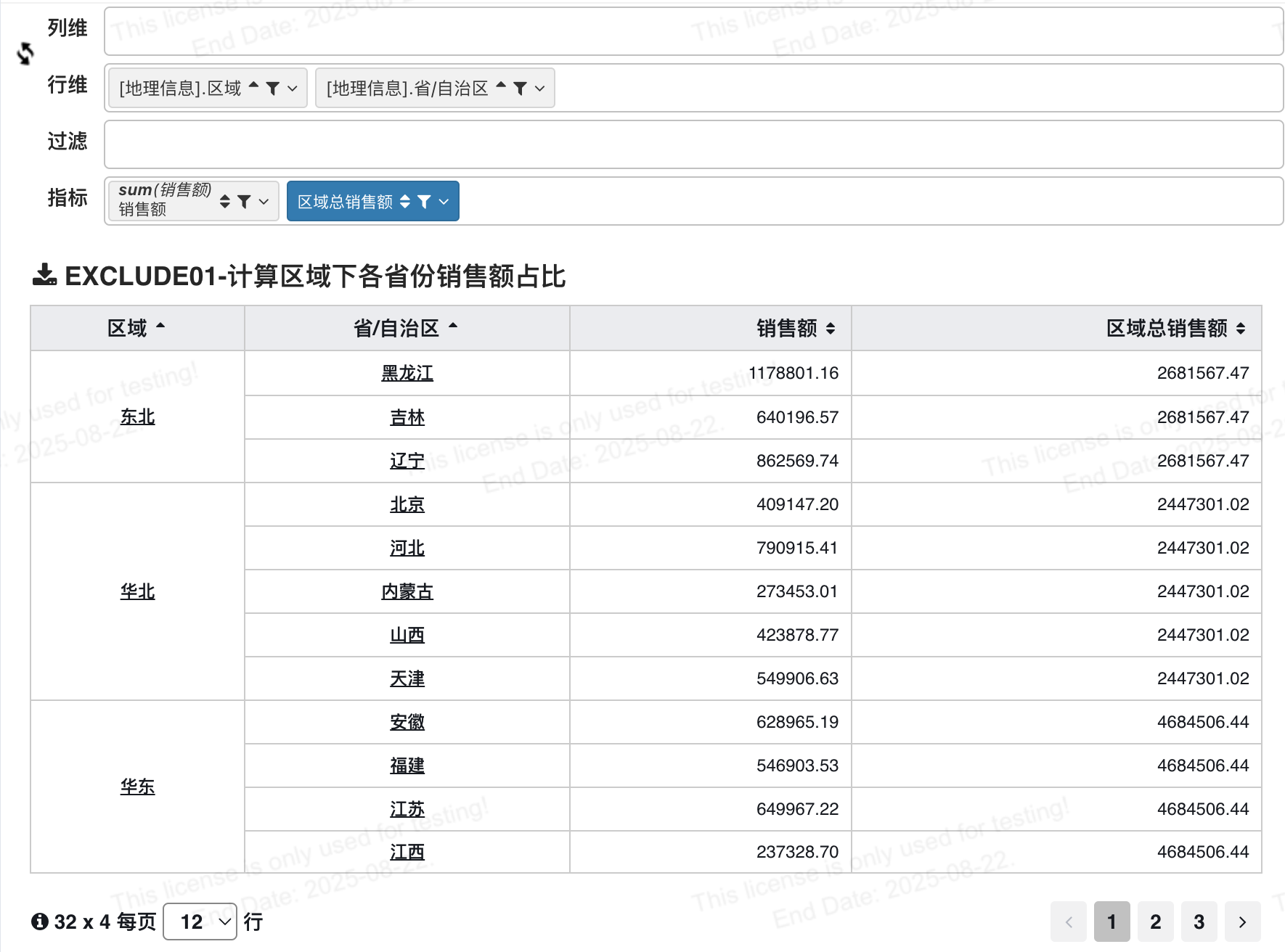
# 计算区域下各省份销售额占比
场景描述 当您在分析区域下各省份的销售额数据情况时,同时还需要查看该区域的总销售数据、以及省份与其的销售额占比时,可以通过exclude函数先计算出除去当前省份后该地区的销售额,再通过聚合方式求和计算出该区域的总额。
字段表达式:
{EXCLUDE `省/自治区` : sum(`销售额`)}
1
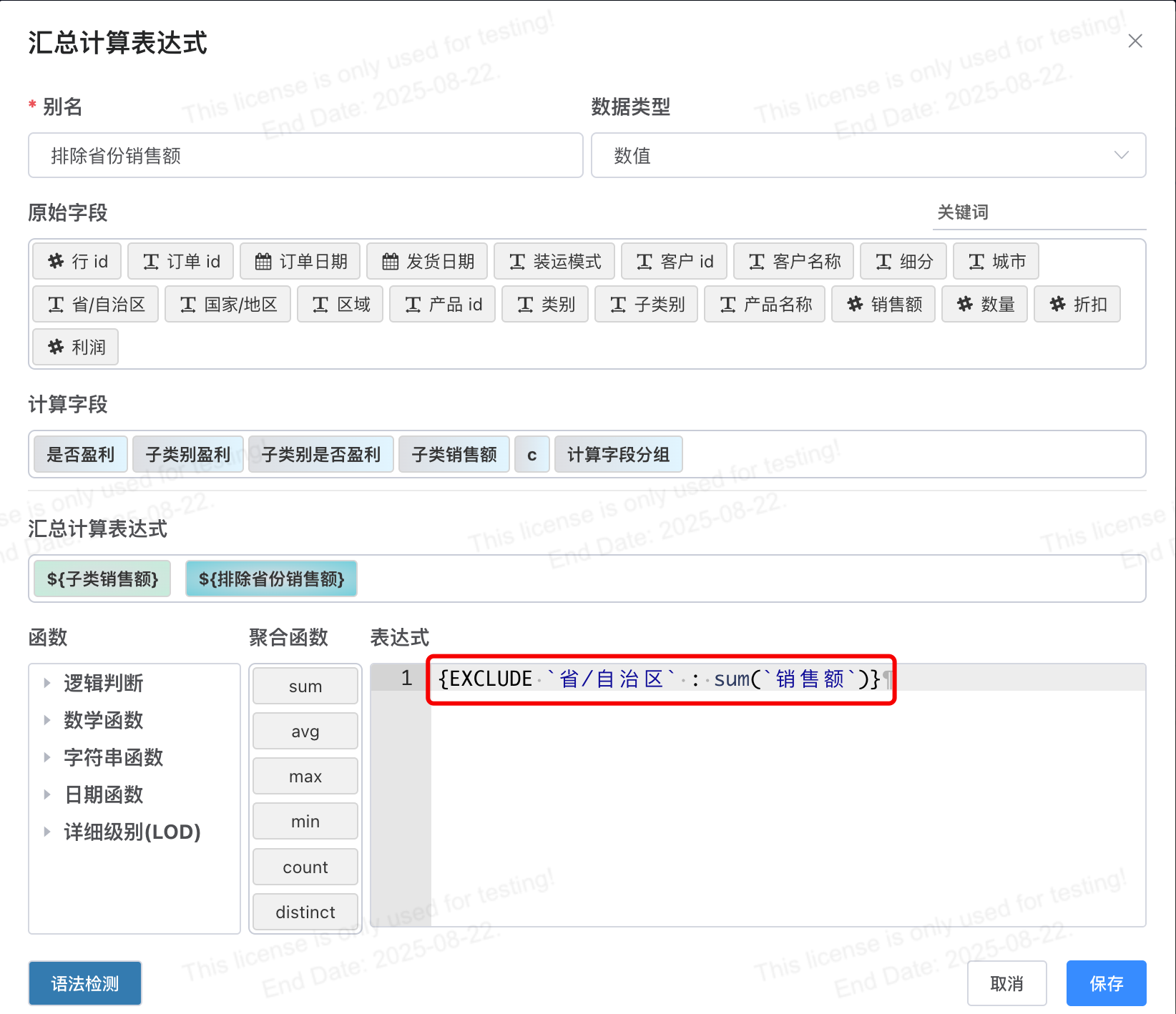
含义:计算除去当前省份后该地区的销售额。
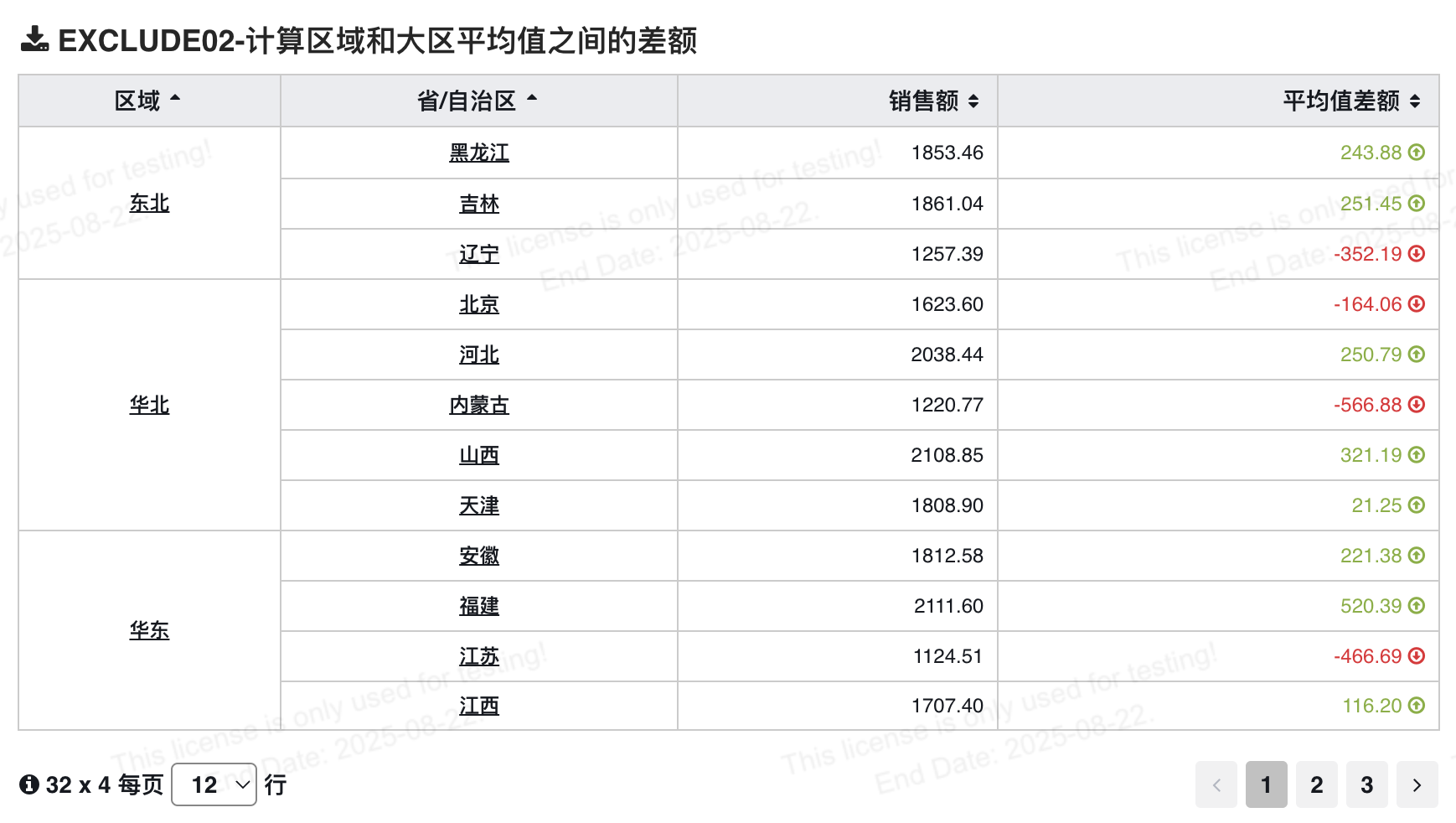
# 计算区域和大区平均值之间的差额
avg(`销售额`) - {EXCLUDE `省/自治区` : avg(`销售额`)}
1
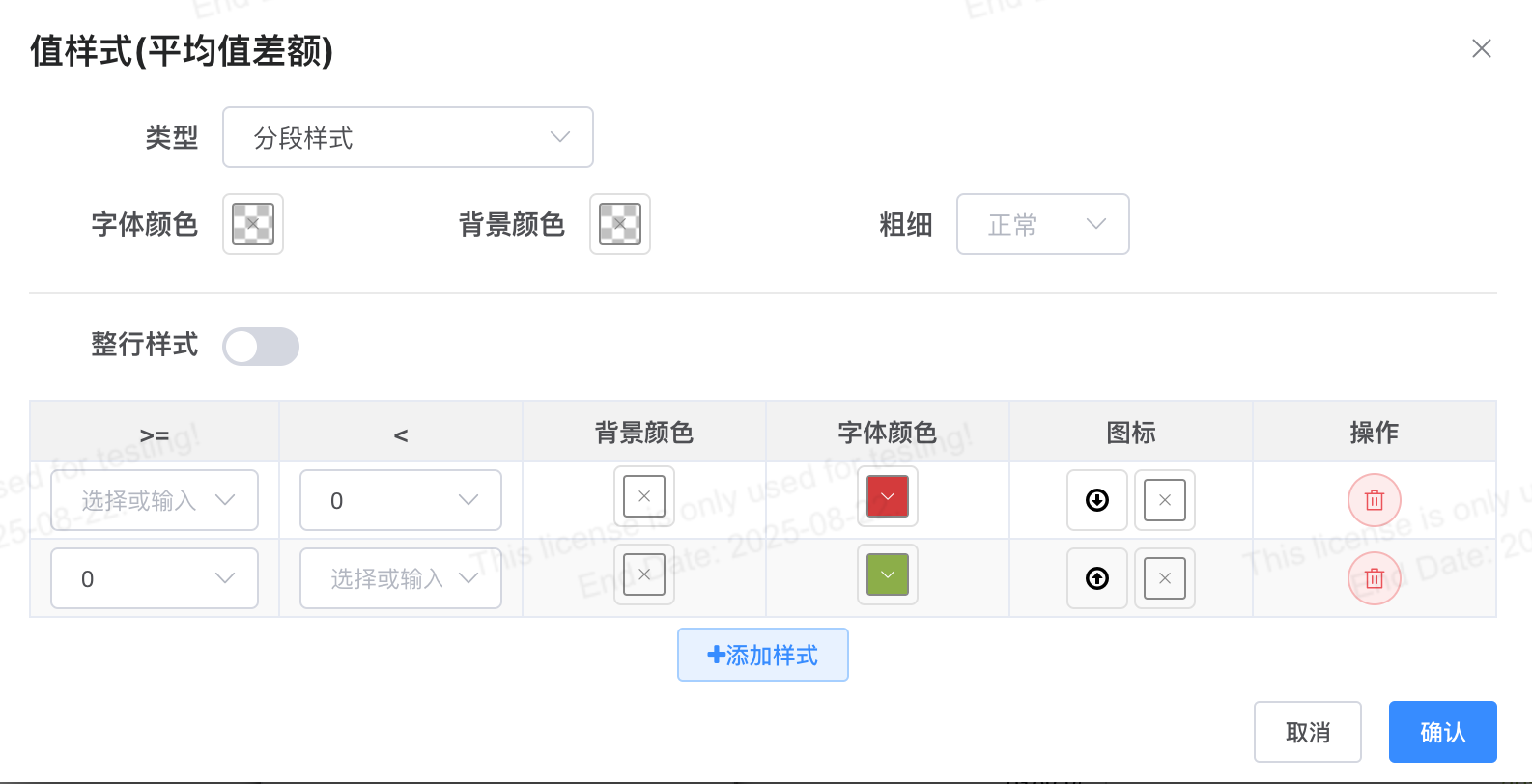
设置分段样式
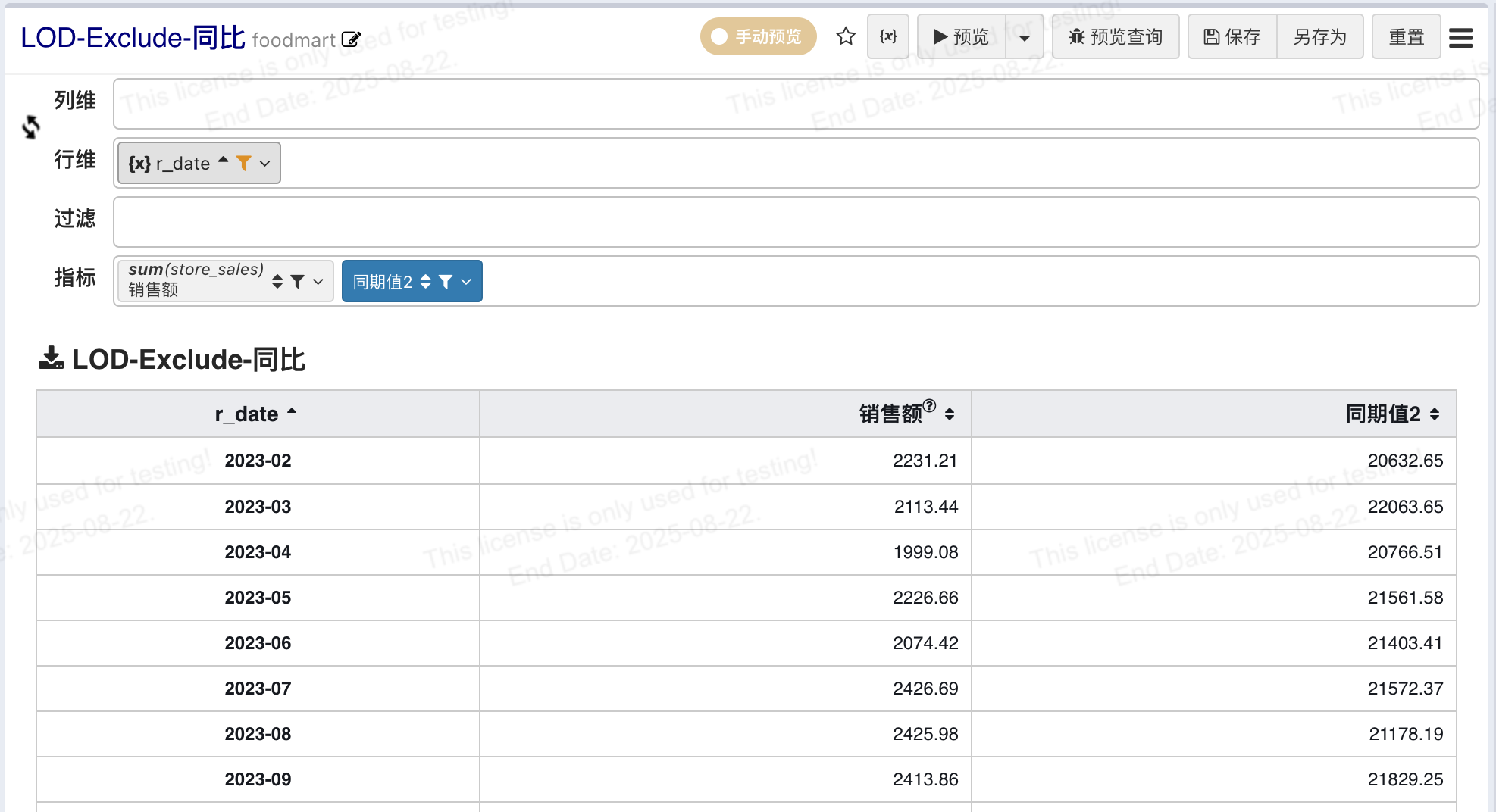
# 同环比计算
从EXCLUDE的定义我们知道,EXCLUDE中的维度定义如果是函数将不会排除任何维度,利用该特性定义EXCLUDE表达式计算去年同期值,如下:
# 同比
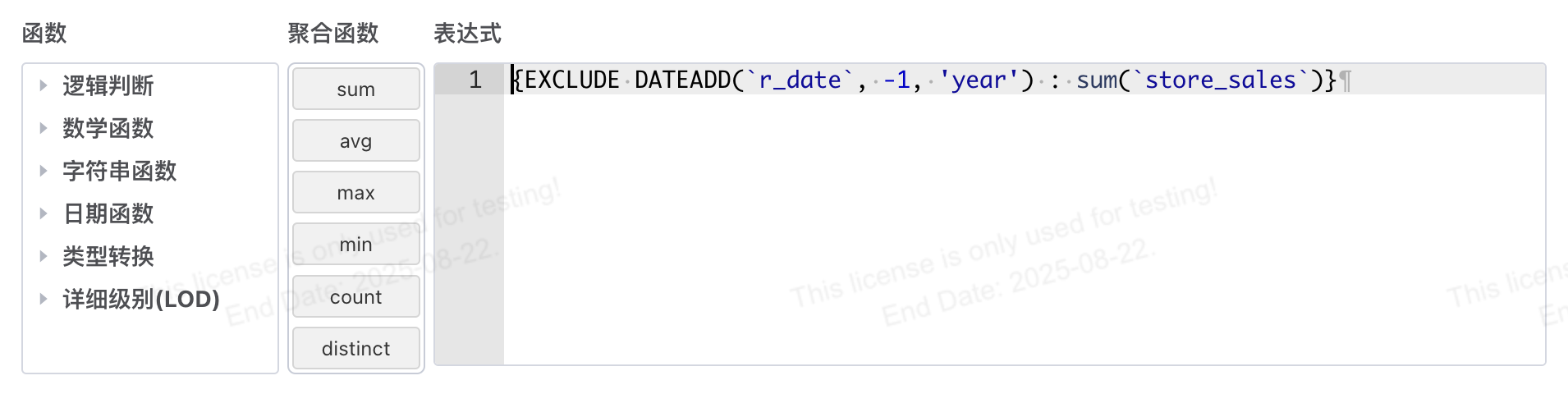
定义汇总表达式
-- 同期值
{EXCLUDE DATEADD(`r_date`, -1, 'year') : sum(`store_sales`)}
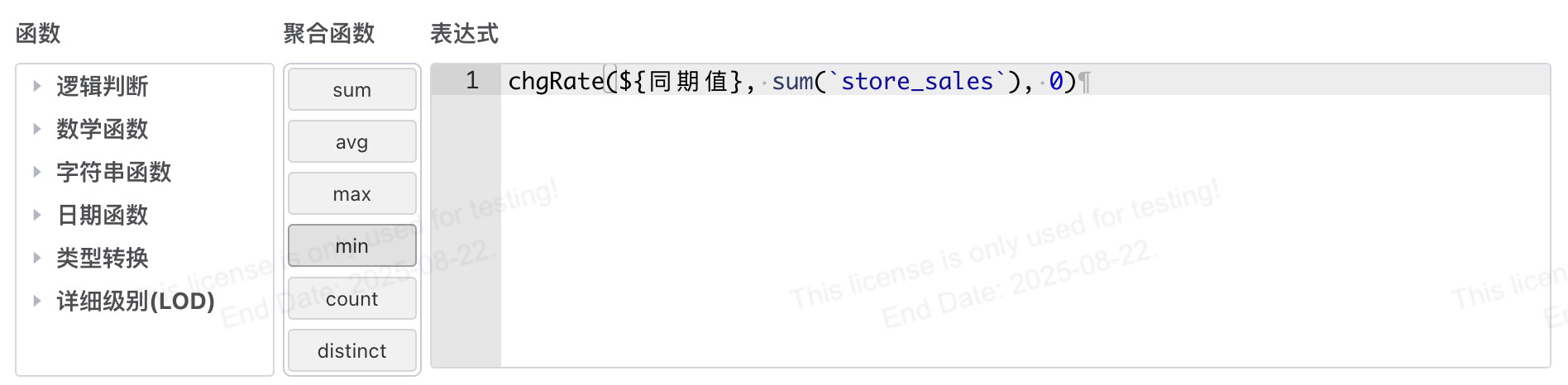
-- 同比
chgRate(${同期值}, sum(`store_sales`), 0)
1
2
3
4
5
2
3
4
5
说明
- 当视图中含有(且必须含有)字段r_date对应的维度时,将基于该字段计算同期值
- r_date可以设置为任意数据颗粒度,如: yyyy-MM、yyyy-Q、yyyy-MM-dd、yyyy-WW
- 基于LOD的同期值可以在任意数据颗粒度使用,您还可以添加任意维度和日期组合分析
- 与指标字段类型同环比区别: 基于LOD的同期值计算运行在数据库层面,数据库会有额外开销
- 且表面不需要去年数据,即: 可以在过滤中对r_date过滤只显示23年的数据,只要数据库中有22年的数据同期值首年的同期值依然能正确计算
# 环比
-- 上月值: 日期往前一个月则为月环比
{EXCLUDE DATEADD(`r_date`, -1, 'month') : sum(`store_sales`)}
-- 上周值:日期往前一周则为周环比
{EXCLUDE DATEADD(`r_date`, -1, 'week') : sum(`store_sales`)}
-- 环比
chgRate(${上月值}, sum(`store_sales`), 0)
1
2
3
4
5
6
7
2
3
4
5
6
7
# 财务毛利率计算
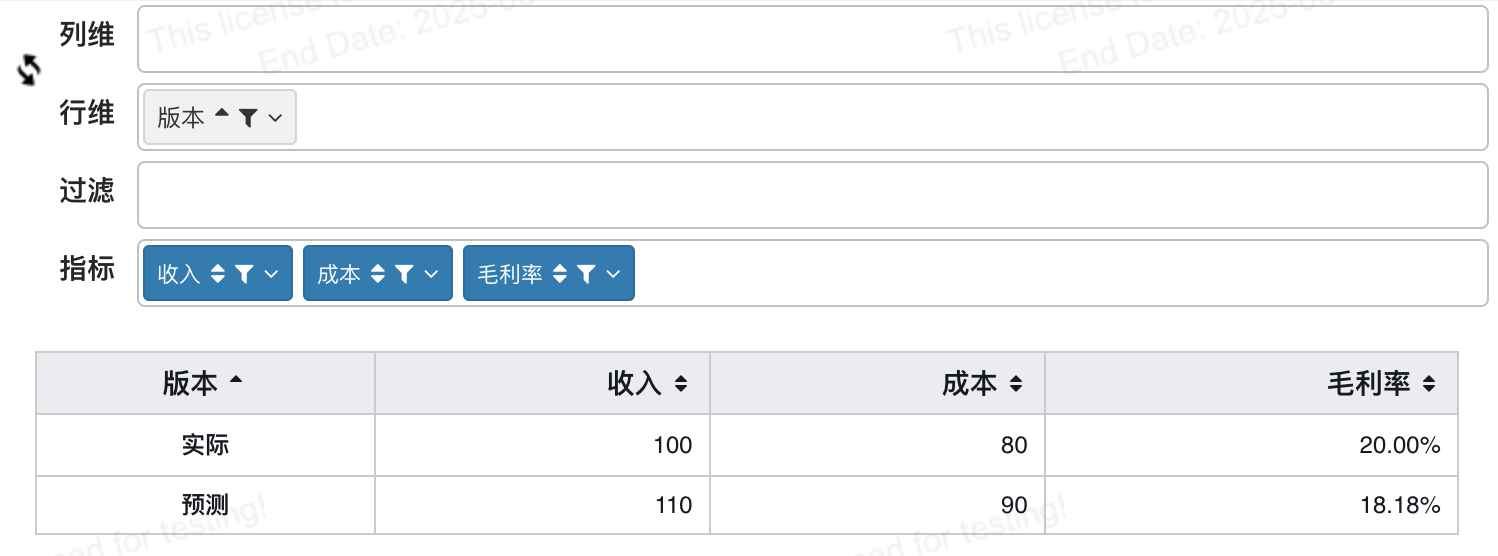
财务还是业务都必然会分析的一个最简单的指标毛利率:
毛利率 GP% = 毛利/收入 =(收入-成本)/收入
| 科目 | 版本 | 金额 |
|---|---|---|
| 收入 | 实际 | 100 |
| 成本 | 实际 | 80 |
| 收入 | 预测 | 110 |
| 成本 | 预测 | 90 |
用 PowerBI 做的话会有以下3步:
收入 = Calculate ( SUM([金额]), Filter('科目表',[科目]="收入"))
成本 = Calculate ( SUM([金额]), Filter('科目表',[科目]="成本"))
毛利率 = Divide ( ([收入] - [成本]) , [收入])
1
2
3
2
3
这一步在我们BI中思路一样,做3个汇总表达式
收入 = sum(IF(`科目`='收入', `金额`, 0))
成本 = sum(IF(`科目`='成本', `金额`, 0))
毛利率 = DIVIDE(${收入}-${成本}, ${收入})
1
2
3
2
3
假如领导说,我要对比 24年实际的毛利率 和 24年预算的毛利率,要对比。PBI 只需要再写3个度量值:
毛利率_24年实际 = Calculate ( [毛利率] , Filter('事实表',[版本]="24年实际"))
毛利率_24年预算 = Calculate ( [毛利率] , Filter('事实表',[版本]="24年预算"))
毛利率_预实差 = [毛利率_24年实际] - [毛利率_24年预算]
1
2
3
2
3
# 不是用详细级别表达式
[毛利率_24年实际] = (
SUM (IF([科目]="收入" and [版本]="24年实际" ,[金额] ,0) -
SUM (IF([科目]="成本" and [版本]="24年实际" ,[金额] ,0)
) /
SUM (IF([科目]="收入" and [版本]="24年实际" ,[金额] ,0)
[毛利率_24年预测] = (
SUM (IF([科目]="收入" and [版本]="24年预测" ,[金额] ,0) -
SUM (IF([科目]="成本" and [版本]="24年预测" ,[金额] ,0)
) /
SUM (IF([科目]="收入" and [版本]="24年预测" ,[金额] ,0)
[差额] = [毛利率_24年实际] - [毛利率_24年预测]
1
2
3
4
5
6
7
8
9
10
11
12
13
2
3
4
5
6
7
8
9
10
11
12
13
思考
可以看到上面虽然计算出来了差额,但是重复的定义了毛利率的计算公式,PowerBI的方案是先过滤表再复用毛利率计算公式,毛利率计算公式统一在毛利率表达式中维护, 如果毛利率计算方案调整只需要修改[毛利率]计算公式表达式即可,但是下面的版本需要修改三个计算公式
- [毛利率]
- [毛利率_24年实际]
- [毛利率_24年预测] 对比之下显然是PowerBI的逻辑更优
# 使用详细级别表达式
用详细级别表达式怎么做呢,我们上面已经定义了毛利率的计算公式,怎么复用公式,而不是新增不同版本的毛利率公式呢
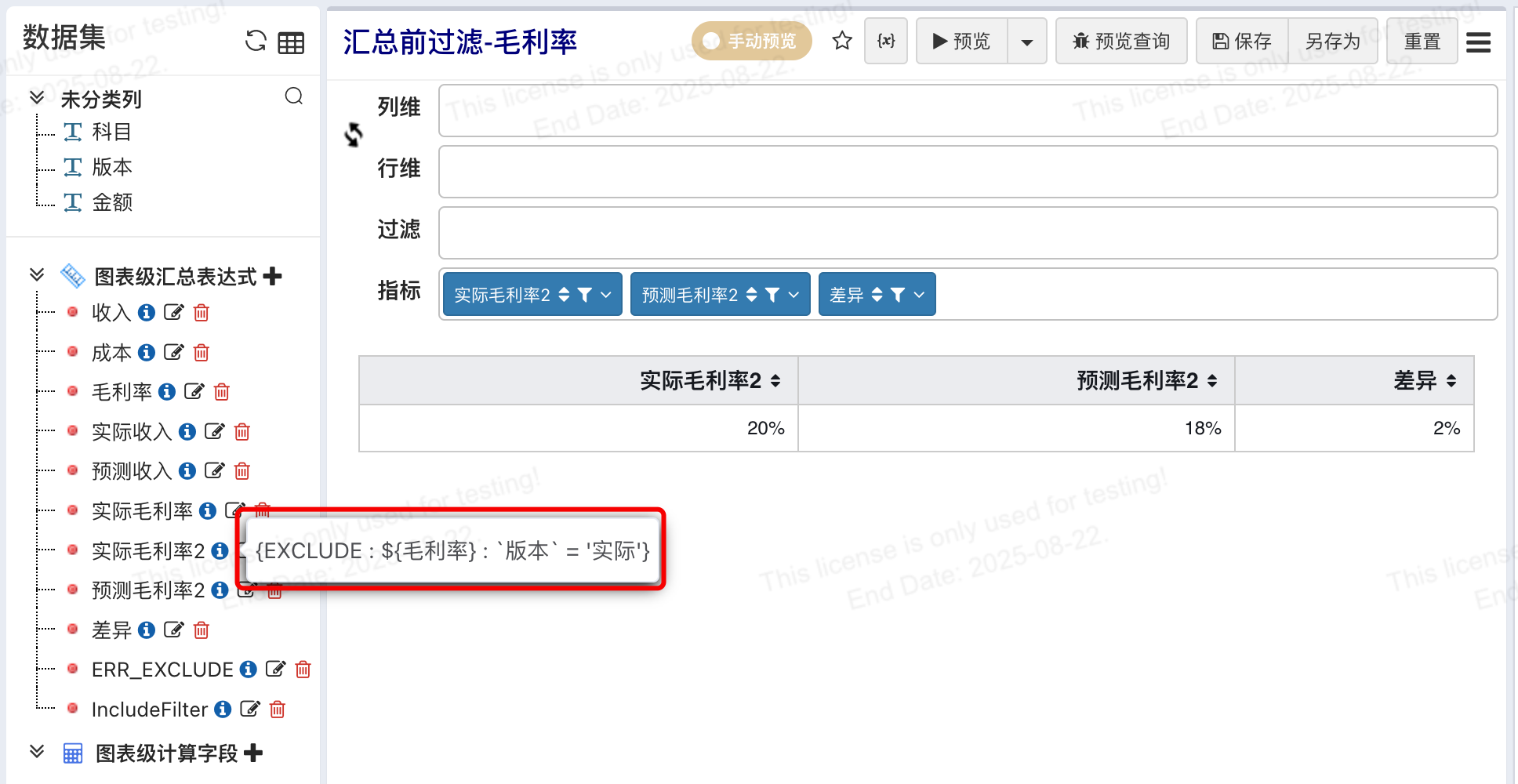
实际毛利率 = {EXCLUDE : ${毛利率} : `版本` = '实际'}
预测毛利率 = {EXCLUDE : ${毛利率} : `版本` = '预测'}
差额 = ${实际毛利率2} - ${预测毛利率2}
1
2
3
2
3
解释
上面的毛利率表达式中,使用EXCLUDE详细级别调整毛利率计算公式,没有排除维度,仅增加了表过滤条件版本 = 'xxx'